"AI scaling myths."
"Scaling will run out. The question is when."
"So far, bigger and bigger language models have proven more and more capable. But does the past predict the future?"
"One popular view is that we should expect the trends that have held so far to continue for many more orders of magnitude, and that it will potentially get us to artificial general intelligence, or AGI."
"What exactly is a 'better' model? Scaling laws only quantify the decrease in perplexity, that is, improvement in how well models can predict the next word in a sequence. Of course, perplexity is more or less irrelevant to end users -- what matters is 'emergent abilities', that is, models' tendency to acquire new capabilities as size increases."
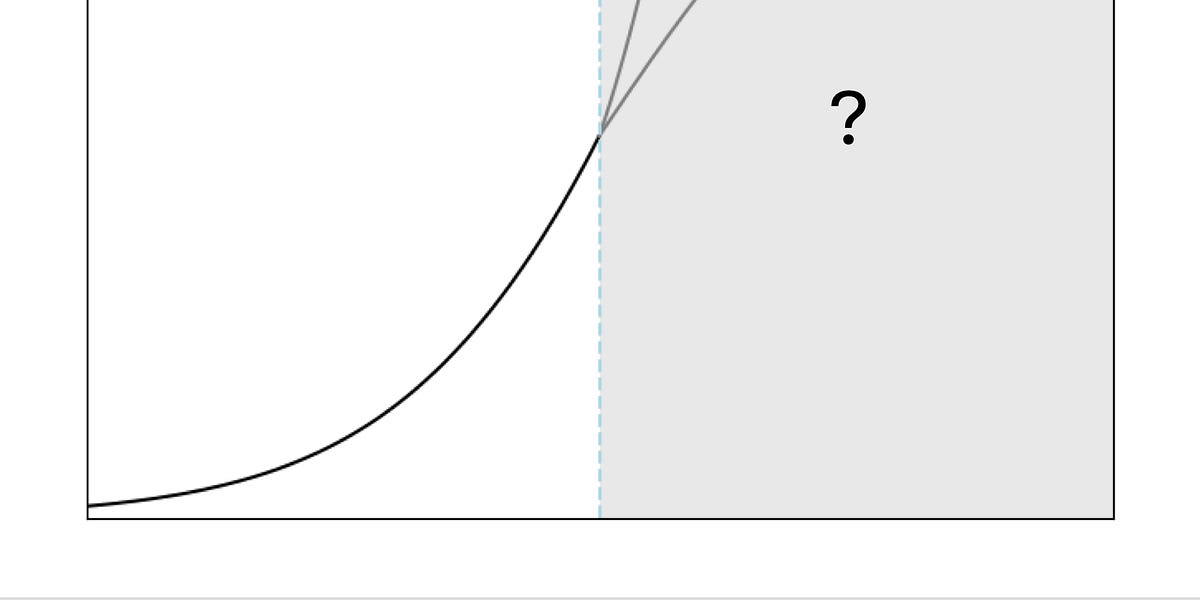
"Emergence is not governed by any law-like behavior. It is true that so far, increases in scale have brought new capabilities. But there is no empirical regularity that gives us confidence that this will continue indefinitely."
They show a graph of airspeed of airplanes and CPU clock speed and show they look like trends you could extrapolate out until they suddenly stop.
The authors break this down into 2 sub-questions: Can more training data be acquired? Can synthetic data solve the problem?
For training data, large language models (LLMs) are already being trained on essentially all of the web, and a huge pile of additional copyrighted material that they might have to stop training on "now that copyright holders have wised up and want to be compensated." They don't mention textbooks but it seems to me like LLMs have been trained on a lot of textbooks.
You might think there's vast amounts of additional data that can be used in the form of YouTube transcripts, but the authors argue most YouTube transcripts are of low quality, and YouTube transcripts are mostly useful for teaching LLMs what spoken conversations look like. (Are they not useful for putting the audio and video together and learning the words for things in the videos?)
They argue synthetic data is sometimes useful for fixing specific gaps in training data and making domain-specific improvements in specific domains like math, code, or low-resource languages. "Self-play", like AlphaZero used to learn to play the Chinese game of Go, is analogous to creating synthetic data, and analogous to "distillation", where a slow and expensive model generates training data for a smaller, more cheaply trained model. Regardless, synthetic data is not a panacea that will lead to AGI.
I find these thoughts on scaling interesting because to me it seems like LLMs are still improving, but I wonder if the improvement is as rapid as before? Perhaps rather than exponential improvement, we're now asymptoting, and will continue to do so until the next algorithmic breakthrough, which might not happen for years, or might happen next week.