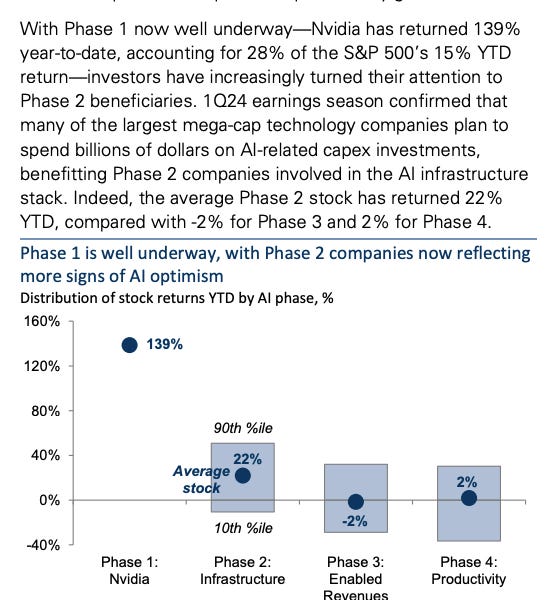
Where does AI research come from? This person got the 2,634 papers from the International Conference on Machine Learning (ICML) 2024 conference, extracted the "institutions" (universities, big companies, and AI startups), and used a 5-step geocoding algorithm to place them on a map.
The papers were downloaded from a site called OpenReview, the affiliations were extracted using a local LLM (gemma-2) from the first page of the PDF, the 5-stop geocoding algorithm uses Nominatim, a local LLM (ollama gemma-2) to verify, a Google search with the LLM parsing the results if the verification fails, and Google Maps paid API if nothing else works, and Python folium was used for creating the map.
What the map reveals is that AI research comes from the US, China, and Europe.
Within the US, it comes from California, the East coast, the Pacific Northwest, and to a lesser extent, the rest of the country. California contributes heavily from both the San Francisco Bay Area (Silicon Valley) and the LA area. The Pacific Northwest is predominantly the Seattle area. New York dominantes on the East Coast but Boston makes a considerable contribution. Various other cities like Austin, TX, Chicago, IL, Madison, WI, Atlanta, GA, and Washington, DC also register.
In China, it's pretty much all Beijing, Shanghai, and Shenzhen. The place names are in Chinese so if you want more, you'll need to read Chinese ;)
Seoul, South Korea, also contributes a lot. Tokyo, Japan also makes a significant contribution.
For Europe, London dominates, followed by Paris, and it looks like, Zurich, Switzerland, Munich, Germany, Amsterdam, in the Netherlands, Berlin, and some from various other places: Warsaw, Copenhagen, Stockholm.
Other notable places include Singapore, Israel, Belgaluru in India, and Australia (Sydney, Melbourne, and Brisbane). Canada has Montreal which is a significant contributor.
My state, Colorado, didn't make a very good showing -- only 3 papers, all from Boulder.
All in all, a pretty interesting map. I wonder what the numbering algorithm is -- it looks pretty smooth. You can zoom in and see contributions from all over the country, all over Europe, and around the world. You can zoom in on the hot spots like Silicon Valley and see where within the SF Bay Area contributions come from (Stanford, Berkeley, the city of SF itself where there are lots of startups, the San Jose region with the tech company heavy hitters, etc).
ICML 2024 Institutions and Associated Papers
#solidstatelife #ai #cartography