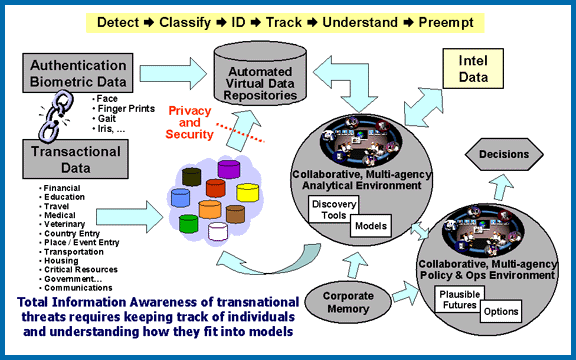
Data Facilitates Surveillance, Privacy Violation, and Manipulation Directly Through Increased Efficiences
Digitisation and distribution (to multiple agencies, organisations, and firms) has been ongoing mostly since the 1960s, though accelerating greatly as disk storage costs passed through the threshold of personal-budget levels in the late 1990s.
I'd been working with industry data in the early 1990s, when several analytic departments at a mid-sized firm might share a couple of gigabytes of mincomputer storage. At a conference during the 1990s, in an audience of several hundred data analysts, only a few hands went up for dealing with GB-scale datasets (the raised hand representing telecoms data as I recall). I realised circa 2000 that storage capable of storing a few hundred bytes data (plenty for a basic dossier) on every individual in a large country, or soon the world, would be within a modest household budget. Shortly afterward, the first news stories of data brokers started appearing, as well as Total Information Awareness, often contracting with those same data brokers.
Early social networking sites were beginning to apply collaborative-filtering moderation systems, which I quickly realised, having helped in the design of several myself, were themselves prodigious personal preferences data collection systems on the part of reviewers --- rating systems like many swords cut two ways; reviewers rate content, but ratings and content preferences also rate the reviewers. (An interesting twist on the Quis custodiet ipsos custodes question.)
In 1900, the only routinely digitised mass citizen data were US Census tabulations, updated decadally and not generally accessible. By 1960, telephone, banking, and airlines data (through SABRE) were digitised, largely as with Census data, on punch cards. Tape and further expansion to credit, insurance, and utility data developed by the 1970s, though punch cards remained in heavy use through the 1980s. The first widespread data privacy outcries came in the 1970s, see for example Newsweek's 1970 article, "The Assault on Privacy (1970)" (PDF), though early infotech pioneers such as packet-switched networking pioneer Paul Baran were writing on data, surveillance, privacy, and ethical concerns in the 1960s. (An aside; those publications are freely available online by RAND at my request.) Marketing and advertising were increasingly represented by the 1990s, as well as healthcare data, though records there remained (and still remain) highly fragmented.
By the 1990s, previously offline court and legal documents began getting digitised in bulk (a practice begun years earlier), sometimes by local courts, more frequently by aggreggation services such as LexisNexis, Westlaw, JustCite, HeinOnline, Bloomberg Law, VLex, LexEur, and others who took advantage of pubic access to compile and store their own aggreggations. Often literally by sending individuals to those rural courthouses mentioned above, and recording or duplicating records, one at a time, from clerks.
Access costs matter. And by costs I'm referring to all inputs, not just money: time, knowledge, rates of availability, periodic caps (e.g., 4 records/hr., but a daily cap of 8 records, 16/week, 32/month, effectively imposing an 8 hr/month access restriction), travel, parsing or interpretation, ability to compile independent archives (rather than relying on the source or origin archive), etc.
Aggregation itself is an invasion of privacy. Reduced search, parsing, and inference-drawing costs enable observation, surveillance, and manipulation.
Reduced costs don't simply facilitate existing uses, but facilitate new, lower-value, activities. This is a rephrasing of the Jevons paradox; increased efficiency increases consumption. Trying to reduce consumption through greater efficiency is like fucking for virginity. Another characteristic is that many of these new uses are of very limited, or negative, social benefit. Very often of fraud, or predatory practices.
Technnology is far less an equaliser than a power multiplier, amplifying inequalities. Information technology especially so.
Data corrupts. Absolute data corrupts absolutely.
#data #InfoTech #surveillance #SurveillanceState #SurveillanceCapitalism #privacy #manipulation #DataAggregation #JevonsParadox #ActonsLaw #PaulBaran