Meg the goat loves to help #shorts #onehappyassfarm #megthegoat #goat #f... https://youtube.com/shorts/3ytyeHgktyw?si=0kBzA6ozORp3Z_9J
One person like that
Meg the goat loves to help #shorts #onehappyassfarm #megthegoat #goat #f... https://youtube.com/shorts/3ytyeHgktyw?si=0kBzA6ozORp3Z_9J
US-Präsidentschaftswahlkampf 2024
Von Hansjürgen Mai
Der parteilose Robert F. Kennedy Jr. zieht seine Kandidatur zurück und unterstützt jetzt offiziell Donald Trump. Seine Familie sieht das als Verrat.
Starting with version 2.33, the GNU C library (glibc) grew the capability to search for shared libraries using additional paths, based on the hardware capabilities of the machine running the code. This was a great boon for x86_64, which was first released in 2003, and has seen many changes in the capabilities of the hardware since then. While it is extremely common for Linux distributions to compile for a baseline which encompasses all of an architecture, there is performance being left on the table by targeting such an old specification and not one of the newer revisions.
One option used internally in glibc and in some other performance-critical libraries is indirect functions, or IFUNCs (see also here) The loader, ld.so uses them to pick function implementations optimized for the available CPU at load time. GCC's (functional multi-versioning (FMV))[https://gcc.gnu.org/wiki/FunctionMultiVersioning] generates several optimized versions of functions, using the IFUNC mechanism so the approprate one is selected at load time. These are strategies which most performance-sensitive libraries do, but not all of them.
With the --tune using package transformation option, Guix implements so-called package multi-versioning, which creates package variants using compiler flags set to use optimizations targeted for a specific CPU.
Finally - and we're getting to the central topic of this post! - glibc since version 2.33 supports another approach: ld.so would search not just the /lib folder, but also the glibc-hwcaps folders, which for x86_64 included /lib/glibc-hwcaps/x86-64-v2, /lib/glibc-hwcaps/x86-64-v3 and /lib/glibc-hwcaps/x86-64-v4, corresponding to the psABI micro-architectures of the x86_64 architecture. This means that if a library was compiled against the baseline of the architecture then it should be installed in /lib, but if it were compiled a second time, this time using (depending on the build instructions) -march=x86-64-v2, then the libraries could be installed in /lib/glibc-hwcaps/x86-64-v2 and then glibc, using ld.so, would choose the correct library at runtime.
These micro-architectures aren't a perfect match for the different hardware available, it is often the case that a particular CPU would satisfy the requirements of one tier and part of the next but would therefore only be able to use the optimizations provided by the first tier and not by the added features that the CPU also supports.
This of course shouldn't be a problem in Guix; it's possible, and even encouraged, to adjust packages to be more useful for one's needs. The problem comes from the search paths: ld.so will only search for the glibc-hwcaps directory if it has already found the base library in the preceding /lib directory. This isn't a problem for distributions following the File System Hierarchy (FHS), but for Guix we will need to ensure that all the different versions of the library will be in the same output.
With a little bit of planning this turns out to not be as hard as it sounds. Lets take for example, the GNU Scientific Library, gsl, a math library which helps with all sorts of numerical analysis. First we create a procedure to generate our 3 additional packages, corresponding to the psABIs that are searched for in the glibc-hwcaps directory.
(define (gsl-hwabi psabi)
(package/inherit gsl
(name (string-append "gsl-" psabi))
(arguments
(substitute-keyword-arguments (package-arguments gsl)
((#:make-flags flags #~'())
#~(append (list (string-append "CFLAGS=-march=" #$psabi)
(string-append "CXXFLAGS=-march=" #$psabi))
#$flags))
((#:configure-flags flags #~'())
#~(append (list (string-append "--libdir=" #$output
"/lib/glibc-hwcaps/" #$psabi))
#$flags))
;; The building machine can't necessarily run the code produced.
((#:tests? _ #t) #f)
((#:phases phases #~%standard-phases)
#~(modify-phases #$phases
(add-after 'install 'remove-extra-files
(lambda _
(for-each (lambda (dir)
(delete-file-recursively (string-append #$output dir)))
(list (string-append "/lib/glibc-hwcaps/" #$psabi "/pkgconfig")
"/bin" "/include" "/share"))))))))
(supported-systems '("x86_64-linux" "powerpc64le-linux"))
(properties `((hidden? . #t)
(tunable? . #f)))))
We remove some directories and any binaries since we only want the libraries produced from the package; we want to use the headers and any other bits from the main package. We then combine all of the pieces together to produce a package which can take advantage of the hardware on which it is run:
(define-public gsl-hwcaps
(package/inherit gsl
(name "gsl-hwcaps")
(arguments
(substitute-keyword-arguments (package-arguments gsl)
((#:phases phases #~%standard-phases)
#~(modify-phases #$phases
(add-after 'install 'install-optimized-libraries
(lambda* (#:key inputs outputs #:allow-other-keys)
(let ((hwcaps "/lib/glibc-hwcaps/"))
(for-each
(lambda (psabi)
(copy-recursively
(string-append (assoc-ref inputs (string-append "gsl-" psabi))
hwcaps psabi)
(string-append #$output hwcaps psabi))
'("x86-64-v2" "x86-64-v3" "x86-64-v4"))))))))
(native-inputs
(modify-inputs (package-native-inputs gsl)
(append (gsl-hwabi "x86-64-v2")
(gsl-hwabi "x86-64-v3")
(gsl-hwabi "x86-64-v4"))))
(supported-systems '("x86_64-linux"))
(properties `((tunable? . #f)))))
In this case the size of the final package is increased by about 13 MiB, from 5.5 MiB to 18 MiB. It is up to you if the speed-up from providing an optimized library is worth the size trade-off.
To use this package as a replacement build input in a package package-input-rewriting/spec is a handy tool:
(define use-glibc-hwcaps
(package-input-rewriting/spec
;; Replace some packages with ones built targeting custom packages build
;; with glibc-hwcaps support.
`(("gsl" . ,(const gsl-hwcaps)))))
(define-public inkscape-with-hwcaps
(package
(inherit (use-glibc-hwcaps inkscape))
(name "inkscape-with-hwcaps")))
Of the Guix supported architectures, x86_64-linux and powerpc64le-linux can both benefit from this new capability.
Through the magic of newer versions of GCC and LLVM it is safe to use these libraries in place of the standard libraries while compiling packages; these compilers know about the glibc-hwcap directories and will purposefully link against the base library during build time, with glibc's ld.so choosing the optimized library at runtime.
One possible use case for these libraries is crating guix packs of packages to run on other systems. By substituting these libraries it becomes possible to crate a guix pack which will have better performance than a standard package used in a guix pack. This works even when the included libraries don't make use of the IFUNCs from glibc or functional multi-versioning from GCC. Providing optimized yet portable pre-compiled binaries is a great way to take advantage of this feature.
GNU Guix is a transactional package manager and an advanced distribution of the GNU system that respects user freedom. Guix can be used on top of any system running the Hurd or the Linux kernel, or it can be used as a standalone operating system distribution for i686, x86_64, ARMv7, AArch64 and POWER9 machines.
In addition to standard package management features, Guix supports transactional upgrades and roll-backs, unprivileged package management, per-user profiles, and garbage collection. When used as a standalone GNU/Linux distribution, Guix offers a declarative, stateless approach to operating system configuration management. Guix is highly customizable and hackable through Guile programming interfaces and extensions to the Scheme language.




Kundgebungen zum Antkriegstag/Weltfriedenstag
In vielen Städten gab es gestern Kundgebungen und Demonstrationen anlässlich der 84. Wiederkehr des faschistischen Überfalls der deutschen Wehrmacht auf unser Nachbarland Polen. Im weiteren Verlauf des 2. Weltkriegs hatten Millionen Menschen ihr Leben verloren.
Nie wieder Krieg!
In dem Bewußtsein, dass sich so ein Verbrechen nie wiederholen darf, haben auch deutsche Politker in den 70-iger Jahren die Entspannungspolitik mitgetragen und zum Erfolg geführt. Heute, 50 Jahre nach diesem Erfolg, wird dagegen wieder versucht mit militärischer Stärke einen Endsieg zu erringen.
Seit mehr als eineinhalb Jahren tobt in der Ukraine ein brutaler Stellungskrieg. Jeden Tag sterben unzählige Soldaten in den Schützengräben, weiterhin werden jeden Tag Männer, Frauen und Kinder verwundet, getötet und vertrieben. Dieser Krieg hat Millionen ihre Heimat geraubt und zur Flucht gezwungen, er zerstört die Umwelt und das Klima.
Unsere Solidarität gilt den Menschen in der Ukraine, in Russland und weltweit, die unter dem Krieg und seinen Folgen leiden. Allen, die desertieren oder sich durch Kriegsdienstverweigerung und Flucht dem Krieg entziehen, allen die Widerstand leisten, gebührt unsere Unterstützung.
Deshlab sind wir auf die Straße gegangen
Hier die ersten Bilder von der Berliner Kundgebung an der Neuen Wache.
Mehr dazu bei https://www.naturfreunde-berlin.de/aufruf-aktionen-antikriegstag-2023
Kategorie[25]: Schule ohne Militär Short-Link dieser Seite: a-fsa.de/d/3vZ
Link zu dieser Seite: https://www.aktion-freiheitstattangst.org/de/articles/8510-20230902-fuer-den-frieden-in-vielen-deutschen-staedten.htm
Link im Tor-Netzwerk: http://a6pdp5vmmw4zm5tifrc3qo2pyz7mvnk4zzimpesnckvzinubzmioddad.onion/de/articles/8510-20230902-fuer-den-frieden-in-vielen-deutschen-staedten.html
Tags: #Antikriegstag #Weltfriedenstag #InternationalerTaggegenAtomtests #UN #USA #GB #F #PAK #IND #RUS #CHIN #KOR #Atomwaffen #Militär #Bundeswehr #Aufrüstung #Waffenexporte #Drohnen #Frieden #Krieg #Friedenserziehung #Menschenrechte #Zivilklauseln

Atomwaffenverbotsvertrag unterschreiben und einhalten!
Heute ist Antikriegstag, von vielen auch Weltfriedenstag genannt, vor 2 Tagen, am 29. August, war der von den Vereinten Nationen beschlossene Internationale Tag gegen Atomtests. Über den heutigen Antikriegstag werden wir morgen nach den heutigen Kundgebungen berichten.
"NUCLEAR SURVIVORS - GEMEINSAM FÜR NUKLEARE GERECHTIGKEIT"
Die Friedensnobelpreisträger, ICAN, berichten uns über ihre laufende Kampagne für den völkerrechtlich verbindlichen UN Atomwaffenverbotsvetrag sowie zum Gedenktag vorgestern.
Seit 1945 wurden mehr als 2.000 Atomwaffentests verzeichnet. In der Grafik links sind nicht nur trockene Zahlen dargestellt, sondern dahinter verbergen sich Geschichten von Gemeinschaften auf der ganzen Welt, die noch heute von den Auswirkungen dieser Tests betroffen sind.
Auch DEUTSCHLAND spielt in dieser Geschichte eine Rolle: In der DDR wurde Uran abgebaut, das in Atomwaffenprogrammen Verwendung fand. Und die Marshallinseln, einst eine deutsche Kolonie, waren Schauplatz von US-Atomwaffentests. Die Folgen dieser Tests reichen bis heute und zeigen, wie dringend nukleare Gerechtigkeit nötig ist.
ICAN Deutschland ruft zur Stärkung der Betroffenenperspektive auf
Zum Internationalen Tag gegen Atomwaffentests erinnert die Internationale Kampagne zur Abschaffung von Atomwaffen (ICAN) an die vielen Menschen, deren Leben, Träume oder Gesundheit durch Atomwaffen zerstört wurden.
Seit 1945 haben nuklear bewaffnete Staaten mehr als 2.000 Atomwaffentests durchgeführt, die Folgen waren und sind entsetzlich: Tausende Menschen starben direkt durch die radioaktive Strahlung, hunderttausende weitere weltweit durch die radioaktive Verseuchung der Atmosphäre. Noch heute sind zahlreiche Inseln und weite Landstriche z.B. in Algerien, Kasachstan oder Australien kontaminiert und unbewohnbar. Überlebende, ihre Kinder und Enkel erkranken noch heute gehäuft an Leukämie und erleiden Fehlgeburten.
“Deutschland trägt eine Mitverantwortung für die Produktion und Tests dieser Waffen. Über Jahrzehnte war Deutschland der wichtigste Uranlieferant für das Atomwaffenprogramm der Sowjetunion und hatte zeitweise viele tausend Atombomben von NATO-Staaten und Sowjetunion auf seinem Territorium stationiert. Bis heute übt die Luftwaffe im Rahmen der sogenannten “nuklearen Teilhabe“ den Einsatz von US-Atombomben in Büchel.”, so Johannes Oehler, Vorstandsmitglied von ICAN Deutschland. Er fordert von der Bundesregierung: “Deutschland soll diese Verantwortung wahrnehmen und den UN-Atomwaffenverbotsvertrag ratifizieren ..."
Setzen wir uns zusammen für eine atomwaffenfreie Welt und Frieden ein! Dazu lädt heute der Weltfriedenstag ein.
Mehr dazu bei https://www.icanw.de/action/atomwaffentests-und-nukleare-gerechtigkeit/
Kategorie[25]: Schule ohne Militär Short-Link dieser Seite: a-fsa.de/d/3vY
Link zu dieser Seite: https://www.aktion-freiheitstattangst.org/de/articles/8509-20230901-internationaler-tag-gegen-atomtests.htm
Link im Tor-Netzwerk: http://a6pdp5vmmw4zm5tifrc3qo2pyz7mvnk4zzimpesnckvzinubzmioddad.onion/de/articles/8509-20230901-internationaler-tag-gegen-atomtests.html
Tags: #Antikriegstag #Weltfriedenstag #InternationalerTaggegenAtomtests #UN #USA #GB #F #PAK #IND #RUS #CHIN #KOR #Atomwaffen #Militär #Bundeswehr #Aufrüstung #Waffenexporte #Drohnen #Frieden #Krieg #Friedenserziehung #Menschenrechte #Zivilklauseln
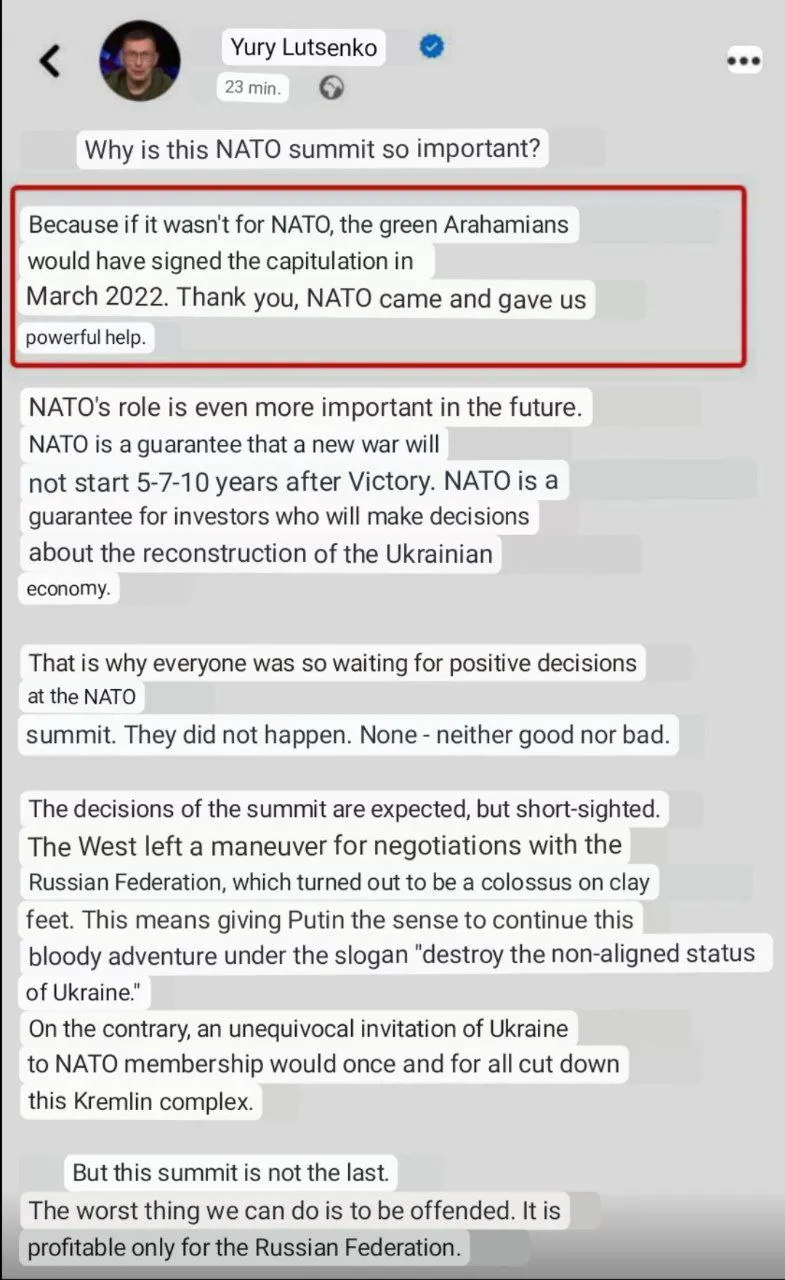
An interesting admission from Ukrainian ex-Interior Minister Lutsenko who openly admitted that if it weren’t for #NATO intervention, #Ukraine would have surrendered in March 2022: That is good to read, it is about #Zelensky and his gang.
Almost at the end of this post
You can read more in this post, but it is a long one, you can skip all, there are only general news, but I recommend scrolling down to watch that short video at the end! #f ** #king interesting
Guix is a handy tool for developers; guix shell, in particular, gives a standalone development environment for your package, no matter what language(s) it’s written in. To benefit from it, you have to initially write a package definition and have it either in Guix proper, in a channel, or directly upstream as a guix.scm file. This last option is appealing: all developers have to do to get set up is clone the project's repository and run guix shell, with no arguments—we looked at the rationale for guix shell in an earlier article.
Development needs go beyond development environments though. How can developers perform continuous integration of their code in Guix build environments? How can they deliver their code straight to adventurous users? This post describes a set of files developers can add to their repository to set up Guix-based development environments, continuous integration, and continuous delivery—all at once.
How do we go about “Guixifying” a repository? The first step, as we’ve seen, will be to add a guix.scm at the root of the repository in question. We’ll take Guile as an example in this post: it’s written in Scheme (mostly) and C, and has a number of dependencies—a C compilation tool chain, C libraries, Autoconf and its friends, LaTeX, and so on. The resulting guix.scm looks like the usual package definition, just without the define-public bit:
;; The ‘guix.scm’ file for Guile, for use by ‘guix shell’.
(use-modules (guix)
(guix build-system gnu)
((guix licenses) #:prefix license:)
(gnu packages autotools)
(gnu packages base)
(gnu packages bash)
(gnu packages bdw-gc)
(gnu packages compression)
(gnu packages flex)
(gnu packages gdb)
(gnu packages gettext)
(gnu packages gperf)
(gnu packages libffi)
(gnu packages libunistring)
(gnu packages linux)
(gnu packages pkg-config)
(gnu packages readline)
(gnu packages tex)
(gnu packages texinfo)
(gnu packages version-control))
(package
(name "guile")
(version "3.0.99-git") ;funky version number
(source #f) ;no source
(build-system gnu-build-system)
(native-inputs
(append (list autoconf
automake
libtool
gnu-gettext
flex
texinfo
texlive-base ;for "make pdf"
texlive-epsf
gperf
git
gdb
strace
readline
lzip
pkg-config)
;; When cross-compiling, a native version of Guile itself is
;; needed.
(if (%current-target-system)
(list this-package)
'())))
(inputs
(list libffi bash-minimal))
(propagated-inputs
(list libunistring libgc))
(native-search-paths
(list (search-path-specification
(variable "GUILE_LOAD_PATH")
(files '("share/guile/site/3.0")))
(search-path-specification
(variable "GUILE_LOAD_COMPILED_PATH")
(files '("lib/guile/3.0/site-ccache")))))
(synopsis "Scheme implementation intended especially for extensions")
(description
"Guile is the GNU Ubiquitous Intelligent Language for Extensions,
and it's actually a full-blown Scheme implementation!")
(home-page "https://www.gnu.org/software/guile/")
(license license:lgpl3+))
Quite a bit of boilerplate, but now someone who’d like to hack on Guile just needs to run:
guix shell
That gives them a shell containing all the dependencies of Guile: those listed above, but also implicit dependencies such as the GCC tool chain, GNU Make, sed, grep, and so on. The chef’s recommendation:
guix shell --container --link-profile
That gives a shell in an isolated container, and all the dependencies show up in $HOME/.guix-profile, which plays well with caches such as config.cache and absolute file names recorded in generated Makefiles and the likes. The fact that the shell runs in a container brings peace of mind: nothing but the current directory and Guile’s dependencies is visible inside the container; nothing from the system can possibly interfere with your development.
Now that we have a package definition, why not also take advantage of it so we can build Guile with Guix? We had left the source field empty, because guix shell above only cares about the inputs of our package—so it can set up the development environment—not about the package itself.
To build the package with Guix, we’ll need to fill out the source field, along these lines:
(use-modules (guix)
(guix git-download) ;for ‘git-predicate’
…)
(define vcs-file?
;; Return true if the given file is under version control.
(or (git-predicate (current-source-directory))
(const #t))) ;not in a Git checkout
(package
(name "guile")
(version "3.0.99-git") ;funky version number
(source (local-file "." "guile-checkout"
#:recursive? #t
#:select? vcs-file?))
…)
Here’s what we changed:
(guix git-download) to our set of imported modules, so we can use its git-predicate procedure.vcs-file? as a procedure that returns true when passed a file that is under version control. For good measure, we add a fallback case for when we’re not in a Git checkout: always return true.source to a local-file—a recursive copy of the current directory ("."), limited to files under version control (the #:select? bit).From there on, our guix.scm file serves a second purpose: it lets us build the software with Guix. The whole point of building with Guix is that it’s a “clean” build—you can be sure nothing from your working tree or system interferes with the build result—and it lets you test a variety of things. First, you can do a plain native build:
guix build -f guix.scm
But you can also build for another system (possibly after setting up offloading or transparent emulation):
guix build -f guix.scm -s aarch64-linux -s riscv64-linux
… or cross-compile:
guix build -f guix.scm --target=x86_64-w64-mingw32
You can also use package transformation options to test package variants:
# What if we built with Clang instead of GCC?
guix build -f guix.scm \
--with-c-toolchain=guile@3.0.99-git=clang-toolchain
# What about that under-tested configure flag?
guix build -f guix.scm \
--with-configure-flag=guile@3.0.99-git=--disable-networking
Handy!
We now have a Git repository containing (among other things) a package definition. Can’t we turn it into a channel? After all, channels are designed to ship package definitions to users, and that’s exactly what we’re doing with our guix.scm.
Turns out we can indeed turn it into a channel, but with one caveat: we must create a separate directory for the .scm file(s) of our channel so that guix pull doesn’t load unrelated .scm files when someone pulls the channel—and in Guile, there are lots of them! So we’ll start like this, keeping a top-level guix.scm symlink for the sake of guix shell:
mkdir -p .guix/modules
mv guix.scm .guix/modules/guile-package.scm
ln -s .guix/modules/guile-package.scm guix.scm
To make it usable as part of a channel, we need to turn our guix.scm file into a module: we do that by changing the use-modules form at the top to a define-module form. We also need to actually export a package variable, with define-public, while still returning the package value at the end of the file so we can still use guix shell and guix build -f guix.scm. The end result looks like this (not repeating things that haven’t changed):
(define-module (guile-package)
#:use-module (guix)
#:use-module (guix git-download) ;for ‘git-predicate’
…)
(define-public guile
(package
(name "guile")
(version "3.0.99-git") ;funky version number
…))
;; Return the package object define above at the end of the module.
guile
We need one last thing: a .guix-channel file so Guix knows where to look for package modules in our repository:
;; This file lets us present this repo as a Guix channel.
(channel
(version 0)
(directory ".guix/modules")) ;look for package modules under .guix/modules/
To recap, we now have these files:
.
├── .guix-channel
├── guix.scm → .guix/modules/guile-package.scm
└── .guix
└── modules
└── guile-package.scm
And that’s it: we have a channel! (We could do better and support channel authentication so users know they’re pulling genuine code. We’ll spare you the details here but it’s worth considering!) Users can pull from this channel by adding it to ~/.config/guix/channels.scm, along these lines:
(append (list (channel
(name 'guile)
(url "https://git.savannah.gnu.org/git/guile.git")
(branch "main")))
%default-channels)
After running guix pull, we can see the new package:
$ guix describe
Generation 264 May 26 2023 16:00:35 (current)
guile 36fd2b4
repository URL: https://git.savannah.gnu.org/git/guile.git
branch: main
commit: 36fd2b4920ae926c79b936c29e739e71a6dff2bc
guix c5bc698
repository URL: https://git.savannah.gnu.org/git/guix.git
commit: c5bc698e8922d78ed85989985cc2ceb034de2f23
$ guix package -A ^guile$
guile 3.0.99-git out,debug guile-package.scm:51:4
guile 3.0.9 out,debug gnu/packages/guile.scm:317:2
guile 2.2.7 out,debug gnu/packages/guile.scm:258:2
guile 2.2.4 out,debug gnu/packages/guile.scm:304:2
guile 2.0.14 out,debug gnu/packages/guile.scm:148:2
guile 1.8.8 out gnu/packages/guile.scm:77:2
$ guix build guile@3.0.99-git
[…]
/gnu/store/axnzbl89yz7ld78bmx72vpqp802dwsar-guile-3.0.99-git-debug
/gnu/store/r34gsij7f0glg2fbakcmmk0zn4v62s5w-guile-3.0.99-git
That’s how, as a developer, you get your software delivered directly into the hands of users! No intermediaries, yet no loss of transparency and provenance tracking.
With that in place, it also becomes trivial for anyone to create Docker images, Deb/RPM packages, or a plain tarball with guix pack:
# How about a Docker image of our Guile snapshot?
guix pack -f docker -S /bin=bin guile@3.0.99-git
# And a relocatable RPM?
guix pack -f rpm -R -S /bin=bin guile@3.0.99-git
We now have an actual channel, but it contains only one package. While we’re at it, we can define package variants in our guile-package.scm file, variants that we want to be able to test as Guile developers—similar to what we did above with transformation options. We can add them like so:
;; This is the ‘.guix/modules/guile-package.scm’ file.
(define-module (guile-package)
…)
(define-public guile
…)
(define (package-with-configure-flags p flags)
"Return P with FLAGS as addition 'configure' flags."
(package/inherit p
(arguments
(substitute-keyword-arguments (package-arguments p)
((#:configure-flags original-flags #~(list))
#~(append #$original-flags #$flags))))))
(define-public guile-without-threads
(package
(inherit (package-with-configure-flags guile
#~(list "--without-threads")))
(name "guile-without-threads")))
(define-public guile-without-networking
(package
(inherit (package-with-configure-flags guile
#~(list "--disable-networking")))
(name "guile-without-networking")))
;; Return the package object defined above at the end of the module.
guile
We can build these variants as regular packages once we’ve pulled the channel. Alternatively, from a checkout of Guile, we can run a command like this one from the top level:
guix build -L $PWD/.guix/modules guile-without-threads
This channel becomes even more interesting once we set up continuous integration (CI). There are several ways to do that.
You can use one of the mainstream continuous integration tools, such as GitLab-CI. To do that, you need to make sure you run jobs in a Docker image or virtual machine that has Guix installed. If we were to do that in the case of Guile, we’d have a job that runs a shell command like this one:
guix build -L $PWD/.guix/modules guile@3.0.99-git
Doing this works great and has the advantage of being easy to achieve on your favorite CI platform.
That said, you’ll really get the most of it by using Cuirass, a CI tool designed for and tightly integrated with Guix. Using it is more work than using a hosted CI tool because you first need to set it up, but that setup phase is greatly simplified if you use its Guix System service. Going back to our example, we give Cuirass a spec file that goes like this:
;; Cuirass spec file to build all the packages of the ‘guile’ channel.
(list (specification
(name "guile")
(build '(channels guile))
(channels
(append (list (channel
(name 'guile)
(url "https://git.savannah.gnu.org/git/guile.git")
(branch "main")))
%default-channels))))
It differs from what you’d do with other CI tools in two important ways:
guile and guix. Indeed, our own guile package depends on many packages provided by the guix channel—GCC, the GNU libc, libffi, and so on. Changes to packages from the guix channel can potentially influence our guile build and this is something we’d like to see as soon as possible as Guile developers.guile channel transparently get pre-built binaries!From a developer’s viewpoint, the end result is this status page listing evaluations : each evaluation is a combination of commits of the guix and guile channels providing a number of jobs —one job per package defined in guile-package.scm times the number of target architectures.
As for substitutes, they come for free! As an example, since our guile jobset is built on ci.guix.gnu.org, which runs guix publish in addition to Cuirass, one automatically gets substitutes for guile builds from ci.guix.gnu.org; no additional work is needed for that.
The Cuirass spec above is convenient: it builds every package in our channel, which includes a few variants. However, this might be insufficiently expressive in some cases: one might want specific cross-compilation jobs, transformations, Docker images, RPM/Deb packages, or even system tests.
To achieve that, you can write a manifest. The one we have for Guile has entries for the package variants we defined above, as well as additional variants and cross builds:
;; This is ‘.guix/manifest.scm’.
(use-modules (guix)
(guix profiles)
(guile-package)) ;import our own package module
(define* (package->manifest-entry* package system
#:key target)
"Return a manifest entry for PACKAGE on SYSTEM, optionally cross-compiled to
TARGET."
(manifest-entry
(inherit (package->manifest-entry package))
(name (string-append (package-name package) "." system
(if target
(string-append "." target)
"")))
(item (with-parameters ((%current-system system)
(%current-target-system target))
package))))
(define native-builds
(manifest
(append (map (lambda (system)
(package->manifest-entry* guile system))
'("x86_64-linux" "i686-linux"
"aarch64-linux" "armhf-linux"
"powerpc64le-linux"))
(map (lambda (guile)
(package->manifest-entry* guile "x86_64-linux"))
(cons (package
(inherit (package-with-c-toolchain
guile
`(("clang-toolchain"
,(specification->package
"clang-toolchain")))))
(name "guile-clang"))
(list guile-without-threads
guile-without-networking
guile-debug
guile-strict-typing))))))
(define cross-builds
(manifest
(map (lambda (target)
(package->manifest-entry* guile "x86_64-linux"
#:target target))
'("i586-pc-gnu"
"aarch64-linux-gnu"
"riscv64-linux-gnu"
"i686-w64-mingw32"
"x86_64-linux-gnu"))))
(concatenate-manifests (list native-builds cross-builds))
We won’t go into the details of this manifest; suffice to say that it provides additional flexibility. We now need to tell Cuirass to build this manifest, which is done with a spec slightly different from the previous one:
;; Cuirass spec file to build all the packages of the ‘guile’ channel.
(list (specification
(name "guile")
(build '(manifest ".guix/manifest.scm"))
(channels
(append (list (channel
(name 'guile)
(url "https://git.savannah.gnu.org/git/guile.git")
(branch "main")))
%default-channels))))
We changed the (build …) part of the spec to '(manifest ".guix/manifest.scm") so that it would pick our manifest, and that’s it!
We picked Guile as the running example in this post and you can see the result here:
.guix-channel;.guix/modules/guile-package.scm with the top-level guix.scm symlink;.guix/manifest.scm.These days, repositories are commonly peppered with dot files for various tools: .envrc, .gitlab-ci.yml, .github/workflows, Dockerfile, .buildpacks, Aptfile, requirements.txt, and whatnot. It may sound like we’re proposing a bunch of additional files, but in fact those files are expressive enough to supersede most or all of those listed above.
With a couple of files, we get support for:
guix shell);guix build);guix pack).At the Guix headquarters, we’re quite happy about the result. We’ve been building a unified tool set for reproducible software deployment; this is an illustration of how you as a developer can benefit from it!
Thanks to Attila Lendvai, Brian Cully, and Ricardo Wurmus for providing feedback on an earlier draft of this post.
GNU Guix is a transactional package manager and an advanced distribution of the GNU system that respects user freedom. Guix can be used on top of any system running the Hurd or the Linux kernel, or it can be used as a standalone operating system distribution for i686, x86_64, ARMv7, AArch64 and POWER9 machines.
In addition to standard package management features, Guix supports transactional upgrades and roll-backs, unprivileged package management, per-user profiles, and garbage collection. When used as a standalone GNU/Linux distribution, Guix offers a declarative, stateless approach to operating system configuration management. Guix is highly customizable and hackable through Guile programming interfaces and extensions to the Scheme language.
Guix is a handy tool for developers; guix shell, in particular, gives a standalone development environment for your package, no matter what language(s) it’s written in. To benefit from it, you have to initially write a package definition and have it either in Guix proper, in a channel, or directly upstream as a guix.scm file. This last option is appealing: all developers have to do to get set up is clone the project's repository and run guix shell, with no arguments—we looked at the rationale for guix shell in an earlier article.
Development needs go beyond development environments though. How can developers perform continuous integration of their code in Guix build environments? How can they deliver their code straight to adventurous users? This post describes a set of files developers can add to their repository to set up Guix-based development environments, continuous integration, and continuous delivery—all at once.
How do we go about “Guixifying” a repository? The first step, as we’ve seen, will be to add a guix.scm at the root of the repository in question. We’ll take Guile as an example in this post: it’s written in Scheme (mostly) and C, and has a number of dependencies—a C compilation tool chain, C libraries, Autoconf and its friends, LaTeX, and so on. The resulting guix.scm looks like the usual package definition, just without the define-public bit:
;; The ‘guix.scm’ file for Guile, for use by ‘guix shell’.
(use-modules (guix)
(guix build-system gnu)
((guix licenses) #:prefix license:)
(gnu packages autotools)
(gnu packages base)
(gnu packages bash)
(gnu packages bdw-gc)
(gnu packages compression)
(gnu packages flex)
(gnu packages gdb)
(gnu packages gettext)
(gnu packages gperf)
(gnu packages libffi)
(gnu packages libunistring)
(gnu packages linux)
(gnu packages pkg-config)
(gnu packages readline)
(gnu packages tex)
(gnu packages texinfo)
(gnu packages version-control))
(package
(name "guile")
(version "3.0.99-git") ;funky version number
(source #f) ;no source
(build-system gnu-build-system)
(native-inputs
(append (list autoconf
automake
libtool
gnu-gettext
flex
texinfo
texlive-base ;for "make pdf"
texlive-epsf
gperf
git
gdb
strace
readline
lzip
pkg-config)
;; When cross-compiling, a native version of Guile itself is
;; needed.
(if (%current-target-system)
(list this-package)
'())))
(inputs
(list libffi bash-minimal))
(propagated-inputs
(list libunistring libgc))
(native-search-paths
(list (search-path-specification
(variable "GUILE_LOAD_PATH")
(files '("share/guile/site/3.0")))
(search-path-specification
(variable "GUILE_LOAD_COMPILED_PATH")
(files '("lib/guile/3.0/site-ccache")))))
(synopsis "Scheme implementation intended especially for extensions")
(description
"Guile is the GNU Ubiquitous Intelligent Language for Extensions,
and it's actually a full-blown Scheme implementation!")
(home-page "https://www.gnu.org/software/guile/")
(license license:lgpl3+))
Quite a bit of boilerplate, but now someone who’d like to hack on Guile just needs to run:
guix shell
That gives them a shell containing all the dependencies of Guile: those listed above, but also implicit dependencies such as the GCC tool chain, GNU Make, sed, grep, and so on. The chef’s recommendation:
guix shell --container --link-profile
That gives a shell in an isolated container, and all the dependencies show up in $HOME/.guix-profile, which plays well with caches such as config.cache and absolute file names recorded in generated Makefiles and the likes. The fact that the shell runs in a container brings peace of mind: nothing but the current directory and Guile’s dependencies is visible inside the container; nothing from the system can possibly interfere with your development.
Now that we have a package definition, why not also take advantage of it so we can build Guile with Guix? We had left the source field empty, because guix shell above only cares about the inputs of our package—so it can set up the development environment—not about the package itself.
To build the package with Guix, we’ll need to fill out the source field, along these lines:
(use-modules (guix)
(guix git-download) ;for ‘git-predicate’
…)
(define vcs-file?
;; Return true if the given file is under version control.
(or (git-predicate (current-source-directory))
(const #t))) ;not in a Git checkout
(package
(name "guile")
(version "3.0.99-git") ;funky version number
(source (local-file "." "guile-checkout"
#:recursive? #t
#:select? vcs-file?))
…)
Here’s what we changed:
(guix git-download) to our set of imported modules, so we can use its git-predicate procedure.vcs-file? as a procedure that returns true when passed a file that is under version control. For good measure, we add a fallback case for when we’re not in a Git checkout: always return true.source to a local-file—a recursive copy of the current directory ("."), limited to files under version control (the #:select? bit).From there on, our guix.scm file serves a second purpose: it lets us build the software with Guix. The whole point of building with Guix is that it’s a “clean” build—you can be sure nothing from your working tree or system interferes with the build result—and it lets you test a variety of things. First, you can do a plain native build:
guix build -f guix.scm
But you can also build for another system (possibly after setting up offloading or transparent emulation):
guix build -f guix.scm -s aarch64-linux -s riscv64-linux
… or cross-compile:
guix build -f guix.scm --target=x86_64-w64-mingw32
You can also use package transformation options to test package variants:
# What if we built with Clang instead of GCC?
guix build -f guix.scm \
--with-c-toolchain=guile@3.0.99-git=clang-toolchain
# What about that under-tested configure flag?
guix build -f guix.scm \
--with-configure-flag=guile@3.0.99-git=--disable-networking
Handy!
We now have a Git repository containing (among other things) a package definition. Can’t we turn it into a channel? After all, channels are designed to ship package definitions to users, and that’s exactly what we’re doing with our guix.scm.
Turns out we can indeed turn it into a channel, but with one caveat: we must create a separate directory for the .scm file(s) of our channel so that guix pull doesn’t load unrelated .scm files when someone pulls the channel—and in Guile, there are lots of them! So we’ll start like this, keeping a top-level guix.scm symlink for the sake of guix shell:
mkdir -p .guix/modules
mv guix.scm .guix/modules/guile-package.scm
ln -s .guix/modules/guile-package.scm guix.scm
To make it usable as part of a channel, we need to turn our guix.scm file into a module: we do that by changing the use-modules form at the top to a define-module form. We also need to actually export a package variable, with define-public, while still returning the package value at the end of the file so we can still use guix shell and guix build -f guix.scm. The end result looks like this (not repeating things that haven’t changed):
(define-module (guile-package)
#:use-module (guix)
#:use-module (guix git-download) ;for ‘git-predicate’
…)
(define-public guile
(package
(name "guile")
(version "3.0.99-git") ;funky version number
…))
;; Return the package object define above at the end of the module.
guile
We need one last thing: a .guix-channel file so Guix knows where to look for package modules in our repository:
;; This file lets us present this repo as a Guix channel.
(channel
(version 0)
(directory ".guix/modules")) ;look for package modules under .guix/modules/
To recap, we now have these files:
.
├── .guix-channel
├── guix.scm → .guix/modules/guile-package.scm
└── .guix
└── modules
└── guile-package.scm
And that’s it: we have a channel! (We could do better and support channel authentication so users know they’re pulling genuine code. We’ll spare you the details here but it’s worth considering!) Users can pull from this channel by adding it to ~/.config/guix/channels.scm, along these lines:
(append (list (channel
(name 'guile)
(url "https://git.savannah.gnu.org/git/guile.git")
(branch "main")))
%default-channels)
After running guix pull, we can see the new package:
$ guix describe
Generation 264 May 26 2023 16:00:35 (current)
guile 36fd2b4
repository URL: https://git.savannah.gnu.org/git/guile.git
branch: main
commit: 36fd2b4920ae926c79b936c29e739e71a6dff2bc
guix c5bc698
repository URL: https://git.savannah.gnu.org/git/guix.git
commit: c5bc698e8922d78ed85989985cc2ceb034de2f23
$ guix package -A ^guile$
guile 3.0.99-git out,debug guile-package.scm:51:4
guile 3.0.9 out,debug gnu/packages/guile.scm:317:2
guile 2.2.7 out,debug gnu/packages/guile.scm:258:2
guile 2.2.4 out,debug gnu/packages/guile.scm:304:2
guile 2.0.14 out,debug gnu/packages/guile.scm:148:2
guile 1.8.8 out gnu/packages/guile.scm:77:2
$ guix build guile@3.0.99-git
[…]
/gnu/store/axnzbl89yz7ld78bmx72vpqp802dwsar-guile-3.0.99-git-debug
/gnu/store/r34gsij7f0glg2fbakcmmk0zn4v62s5w-guile-3.0.99-git
That’s how, as a developer, you get your software delivered directly into the hands of users! No intermediaries, yet no loss of transparency and provenance tracking.
With that in place, it also becomes trivial for anyone to create Docker images, Deb/RPM packages, or a plain tarball with guix pack:
# How about a Docker image of our Guile snapshot?
guix pack -f docker -S /bin=bin guile@3.0.99-git
# And a relocatable RPM?
guix pack -f rpm -R -S /bin=bin guile@3.0.99-git
We now have an actual channel, but it contains only one package. While we’re at it, we can define package variants in our guile-package.scm file, variants that we want to be able to test as Guile developers—similar to what we did above with transformation options. We can add them like so:
;; This is the ‘.guix/modules/guile-package.scm’ file.
(define-module (guile-package)
…)
(define-public guile
…)
(define (package-with-configure-flags p flags)
"Return P with FLAGS as addition 'configure' flags."
(package/inherit p
(arguments
(substitute-keyword-arguments (package-arguments p)
((#:configure-flags original-flags #~(list))
#~(append #$original-flags #$flags))))))
(define-public guile-without-threads
(package
(inherit (package-with-configure-flags guile
#~(list "--without-threads")))
(name "guile-without-threads")))
(define-public guile-without-networking
(package
(inherit (package-with-configure-flags guile
#~(list "--disable-networking")))
(name "guile-without-networking")))
;; Return the package object defined above at the end of the module.
guile
We can build these variants as regular packages once we’ve pulled the channel. Alternatively, from a checkout of Guile, we can run a command like this one from the top level:
guix build -L $PWD/.guix/modules guile-without-threads
This channel becomes even more interesting once we set up continuous integration (CI). There are several ways to do that.
You can use one of the mainstream continuous integration tools, such as GitLab-CI. To do that, you need to make sure you run jobs in a Docker image or virtual machine that has Guix installed. If we were to do that in the case of Guile, we’d have a job that runs a shell command like this one:
guix build -L $PWD/.guix/modules guile@3.0.99-git
Doing this works great and has the advantage of being easy to achieve on your favorite CI platform.
That said, you’ll really get the most of it by using Cuirass, a CI tool designed for and tightly integrated with Guix. Using it is more work than using a hosted CI tool because you first need to set it up, but that setup phase is greatly simplified if you use its Guix System service. Going back to our example, we give Cuirass a spec file that goes like this:
;; Cuirass spec file to build all the packages of the ‘guile’ channel.
(list (specification
(name "guile")
(build '(channels guile))
(channels
(append (list (channel
(name 'guile)
(url "https://git.savannah.gnu.org/git/guile.git")
(branch "main")))
%default-channels))))
It differs from what you’d do with other CI tools in two important ways:
guile and guix. Indeed, our own guile package depends on many packages provided by the guix channel—GCC, the GNU libc, libffi, and so on. Changes to packages from the guix channel can potentially influence our guile build and this is something we’d like to see as soon as possible as Guile developers.guile channel transparently get pre-built binaries!From a developer’s viewpoint, the end result is this status page listing evaluations : each evaluation is a combination of commits of the guix and guile channels providing a number of jobs —one job per package defined in guile-package.scm times the number of target architectures.
As for substitutes, they come for free! As an example, since our guile jobset is built on ci.guix.gnu.org, which runs guix publish in addition to Cuirass, one automatically gets substitutes for guile builds from ci.guix.gnu.org; no additional work is needed for that.
The Cuirass spec above is convenient: it builds every package in our channel, which includes a few variants. However, this might be insufficiently expressive in some cases: one might want specific cross-compilation jobs, transformations, Docker images, RPM/Deb packages, or even system tests.
To achieve that, you can write a manifest. The one we have for Guile has entries for the package variants we defined above, as well as additional variants and cross builds:
;; This is ‘.guix/manifest.scm’.
(use-modules (guix)
(guix profiles)
(guile-package)) ;import our own package module
(define* (package->manifest-entry* package system
#:key target)
"Return a manifest entry for PACKAGE on SYSTEM, optionally cross-compiled to
TARGET."
(manifest-entry
(inherit (package->manifest-entry package))
(name (string-append (package-name package) "." system
(if target
(string-append "." target)
"")))
(item (with-parameters ((%current-system system)
(%current-target-system target))
package))))
(define native-builds
(manifest
(append (map (lambda (system)
(package->manifest-entry* guile system))
'("x86_64-linux" "i686-linux"
"aarch64-linux" "armhf-linux"
"powerpc64le-linux"))
(map (lambda (guile)
(package->manifest-entry* guile "x86_64-linux"))
(cons (package
(inherit (package-with-c-toolchain
guile
`(("clang-toolchain"
,(specification->package
"clang-toolchain")))))
(name "guile-clang"))
(list guile-without-threads
guile-without-networking
guile-debug
guile-strict-typing))))))
(define cross-builds
(manifest
(map (lambda (target)
(package->manifest-entry* guile "x86_64-linux"
#:target target))
'("i586-pc-gnu"
"aarch64-linux-gnu"
"riscv64-linux-gnu"
"i686-w64-mingw32"
"x86_64-linux-gnu"))))
(concatenate-manifests (list native-builds cross-builds))
We won’t go into the details of this manifest; suffice to say that it provides additional flexibility. We now need to tell Cuirass to build this manifest, which is done with a spec slightly different from the previous one:
;; Cuirass spec file to build all the packages of the ‘guile’ channel.
(list (specification
(name "guile")
(build '(manifest ".guix/manifest.scm"))
(channels
(append (list (channel
(name 'guile)
(url "https://git.savannah.gnu.org/git/guile.git")
(branch "main")))
%default-channels))))
We changed the (build …) part of the spec to '(manifest ".guix/manifest.scm") so that it would pick our manifest, and that’s it!
We picked Guile as the running example in this post and you can see the result here:
.guix-channel;.guix/modules/guile-package.scm with the top-level guix.scm symlink;.guix/manifest.scm.These days, repositories are commonly peppered with dot files for various tools: .envrc, .gitlab-ci.yml, .github/workflows, Dockerfile, .buildpacks, Aptfile, requirements.txt, and whatnot. It may sound like we’re proposing a bunch of additional files, but in fact those files are expressive enough to supersede most or all of those listed above.
With a couple of files, we get support for:
guix shell);guix build);guix pack).At the Guix headquarters, we’re quite happy about the result. We’ve been building a unified tool set for reproducible software deployment; this is an illustration of how you as a developer can benefit from it!
Thanks to Attila Lendvai, Brian Cully, and Ricardo Wurmus for providing feedback on an earlier draft of this post.
GNU Guix is a transactional package manager and an advanced distribution of the GNU system that respects user freedom. Guix can be used on top of any system running the Hurd or the Linux kernel, or it can be used as a standalone operating system distribution for i686, x86_64, ARMv7, AArch64 and POWER9 machines.
In addition to standard package management features, Guix supports transactional upgrades and roll-backs, unprivileged package management, per-user profiles, and garbage collection. When used as a standalone GNU/Linux distribution, Guix offers a declarative, stateless approach to operating system configuration management. Guix is highly customizable and hackable through Guile programming interfaces and extensions to the Scheme language.
Good evening, hackers. Today's missive is more of a massive, in the sense that it's another presentation transcript-alike; these things always translate to many vertical pixels.
In my defense, I hardly ever give a presentation twice, so not only do I miss out on the usual per-presentation cost amortization and on the incremental improvements of repetition, the more dire error is that whatever message I might have can only ever reach a subset of those that it might interest; here at least I can be more or less sure that if the presentation would interest someone, that they will find it.
So for the time being I will try to share presentations here, in the spirit of, well, why the hell not.
A functional intermediate language
10 May 2023 – Spritely
Andy Wingo
Igalia, S.L.
Last week I gave a training talk to Spritely Institute collaborators on the intermediate representation used by Guile's compiler.
Compiler: Front-end to Middle-end to Back-end
Middle-end spans gap between high-level source code (AST) and low-level machine code
Programs in middle-end expressed in intermediate language
CPS Soup is the language of Guile’s middle-end
An intermediate representation (IR) (or intermediate language , IL) is just another way to express a computer program. Specifically it's the kind of language that is appropriate for the middle-end of a compiler, and by "appropriate" I meant that an IR serves a purpose: there has to be a straightforward transformation to the IR from high-level abstract syntax trees (ASTs) from the front-end, and there has to be a straightforward translation from IR to machine code.
There are also usually a set of necessary source-to-source transformations on IR to "lower" it, meaning to make it closer to the back-end than to the front-end. There are usually a set of optional transformations to the IR to make the program run faster or allocate less memory or be more simple: these are the optimizations.
"CPS soup" is Guile's IR. This talk presents the essentials of CPS soup in the context of more traditional IRs.
High-level:
(+ 1 (if x 42 69))
Low-level:
cmpi $x, #f
je L1
movi $t, 42
j L2
L1:
movi $t, 69
L2:
addi $t, 1
How to get from here to there?
Before we dive in, consider what we might call the dynamic range of an intermediate representation: we start with what is usually an algebraic formulation of a program and we need to get down to a specific sequence of instructions operating on registers (unlimited in number, at this stage; allocating to a fixed set of registers is a back-end concern), with explicit control flow between them. What kind of a language might be good for this? Let's attempt to answer the question by looking into what the standard solutions are for this problem domain.
Control-flow graph (CFG)
graph := array<block>
block := tuple<preds, succs, insts>
inst := goto B
| if x then BT else BF
| z = const C
| z = add x, y
...
BB0: if x then BB1 else BB2
BB1: t = const 42; goto BB3
BB2: t = const 69; goto BB3
BB3: t2 = addi t, 1; ret t2
Assignment, not definition
Of course in the early days, there was no intermediate language; compilers translated ASTs directly to machine code. It's been a while since I dove into all this but the milestone I have in my head is that it's the 70s when compiler middle-ends come into their own right, with Fran Allen's work on flow analysis and optimization.
In those days the intermediate representation for a compiler was a graph of basic blocks, but unlike today the paradigm was assignment to locations rather than definition of values. By that I mean that in our example program, we get t assigned to in two places (BB1 and BB2); the actual definition of t is implicit, as a storage location, and our graph consists of assignments to the set of storage locations in the program.
Static single assignment (SSA) CFG
graph := array<block>
block := tuple<preds, succs, phis, insts>
phi := z := φ(x, y, ...)
inst := z := const C
| z := add x, y
...
BB0: if x then BB1 else BB2
BB1: v0 := const 42; goto BB3
BB2: v1 := const 69; goto BB3
BB3: v2 := φ(v0,v1); v3:=addi t,1; ret v3
Phi is phony function: v2 is v0 if coming from first predecessor, or v1 from second predecessor
These days we still live in Fran Allen's world, but with a twist: we no longer model programs as graphs of assignments, but rather graphs of definitions. The introduction in the mid-80s of so-called "static single-assignment" (SSA) form graphs mean that instead of having two assignments to t, we would define two different values v0 and v1. Then later instead of reading the value of the storage location associated with t, we define v2 to be either v0 or v1: the former if we reach the use of t in BB3 from BB1, the latter if we are coming from BB2.
If you think on the machine level, in terms of what the resulting machine code will be, this either function isn't a real operation; probably register allocation will put v0, v1, and v2 in the same place, say $rax. The function linking the definition of v2 to the inputs v0 and v1 is purely notational; in a way, you could say that it is phony , or not real. But when the creators of SSA went to submit this notation for publication they knew that they would need something that sounded more rigorous than "phony function", so they instead called it a "phi" (φ) function. Really.
Refinement: phi variables are basic block args
graph := array<block>
block := tuple<preds, succs, args, insts>
Inputs of phis implicitly computed from preds
BB0(a0): if a0 then BB1() else BB2()
BB1(): v0 := const 42; BB3(v0)
BB2(): v1 := const 69; BB3(v1)
BB3(v2): v3 := addi v2, 1; ret v3
SSA is still where it's at, as a conventional solution to the IR problem. There have been some refinements, though. I learned of one of them from MLton; I don't know if they were first but they had the idea of interpreting phi variables as arguments to basic blocks. In this formulation, you don't have explicit phi instructions; rather the "v2 is either v1 or v0" property is expressed by v2 being a parameter of a block which is "called" with either v0 or v1 as an argument. It's the same semantics, but an interesting notational change.
Often nice to know how a block ends (e.g. to compute phi input vars)
graph := array<block>
block := tuple<preds, succs, args, insts,
control>
control := if v then L1 else L2
| L(v, ...)
| switch(v, L1, L2, ...)
| ret v
One other refinement to SSA is to note that basic blocks consist of some number of instructions that can define values or have side effects but which otherwise exhibit fall-through control flow, followed by a single instruction that transfers control to another block. We might as well store that control instruction separately; this would let us easily know how a block ends, and in the case of phi block arguments, easily say what values are the inputs of a phi variable. So let's do that.
Block successors directly computable from control
Predecessors graph is inverse of successors graph
graph := array<block>
block := tuple<args, insts, control>
Can we simplify further?
At this point we notice that we are repeating ourselves; the successors of a block can be computed directly from the block's terminal control instruction. Let's drop those as a distinct part of a block, because when you transform a program it's unpleasant to have to needlessly update something in two places.
While we're doing that, we note that the predecessors array is also redundant, as it can be computed from the graph of block successors. Here we start to wonder: am I simpliying or am I removing something that is fundamental to the algorithmic complexity of the various graph transformations that I need to do? We press on, though, hoping we will get somewhere interesting.
Ceremony about managing insts; array or doubly-linked list?
Nonuniformity: “local” vs ‘`global’' transformations
Optimizations transform graph A to graph B; mutability complicates this task
Recall that the context for this meander is Guile's compiler, which is written in Scheme. Scheme doesn't have expandable arrays built-in. You can build them, of course, but it is annoying. Also, in Scheme-land, functions with side-effects are conventionally suffixed with an exclamation mark; after too many of them, both the writer and the reader get fatigued. I know it's a silly argument but it's one of the things that made me grumpy about basic blocks.
If you permit me to continue with this introspection, I find there is an uneasy relationship between instructions and locations in an IR that is structured around basic blocks. Do instructions live in a function-level array and a basic block is an array of instruction indices? How do you get from instruction to basic block? How would you hoist an instruction to another basic block, might you need to reallocate the block itself?
And when you go to transform a graph of blocks... well how do you do that? Is it in-place? That would be efficient; but what if you need to refer to the original program during the transformation? Might you risk reading a stale graph?
It seems to me that there are too many concepts, that in the same way that SSA itself moved away from assignment to a more declarative language, that perhaps there is something else here that might be more appropriate to the task of a middle-end.
Blocks: label with args sufficient; “containing” multiple instructions is superfluous
Unify the two ways of naming values: every var is a phi
graph := array<block>
block := tuple<args, inst>
inst := L(expr)
| if v then L1() else L2()
...
expr := const C
| add x, y
...
I took a number of tacks here, but the one I ended up on was to declare that basic blocks themselves are redundant. Instead of containing an array of instructions with fallthrough control-flow, why not just make every instruction a control instruction? (Yes, there are arguments against this, but do come along for the ride, we get to a funny place.)
While you are doing that, you might as well unify the two ways in which values are named in a MLton-style compiler: instead of distinguishing between basic block arguments and values defined within a basic block, we might as well make all names into basic block arguments.
Array of blocks implicitly associates a label with each block
Optimizations add and remove blocks; annoying to have dead array entries
Keep labels as small integers, but use a map instead of an array
graph := map<label, block>
In the traditional SSA CFG IR, a graph transformation would often not touch the structure of the graph of blocks. But now having given each instruction its own basic block, we find that transformations of the program necessarily change the graph. Consider an instruction that we elide; before, we would just remove it from its basic block, or replace it with a no-op. Now, we have to find its predecessor(s), and forward them to the instruction's successor. It would be useful to have a more capable data structure to represent this graph. We might as well keep labels as being small integers, but allow for sparse maps and growth by using an integer-specialized map instead of an array.
graph := map<label, **cont** >
cont := tuple<args, **term** >
term := **continue** to L
with values from expr
| if v then L1() else L2()
...
expr := const C
| add x, y
...
SSA is CPS
This is exactly what CPS soup is! We came at it "from below", so to speak; instead of the heady fumes of the lambda calculus, we get here from down-to-earth basic blocks. (If you prefer the other way around, you might enjoy this article from a long time ago.) The remainder of this presentation goes deeper into what it is like to work with CPS soup in practice.
BB0(a0): if a0 then BB1() else BB2()
BB1(): v0 := const 42; BB3(v0)
BB2(): v1 := const 69; BB3(v1)
BB3(v2): v3 := addi v2, 1; ret v3
What vars are “in scope” at BB3? a0 and v2.
Not v0; not all paths from BB0 to BB3 define v0.
a0 always defined: its definition dominates all uses.
BB0 dominates BB3: All paths to BB3 go through BB0.
Before moving on, though, we should discuss what it means in an SSA-style IR that variables are defined rather than assigned. If you consider variables as locations to which values can be assigned and which initially hold garbage, you can read them at any point in your program. You might get garbage, though, if the variable wasn't assigned something sensible on the path that led to reading the location's value. It sounds bonkers but it is still the C and C++ semantic model.
If we switch instead to a definition-oriented IR, then a variable never has garbage; the single definition always precedes any uses of the variable. That is to say that all paths from the function entry to the use of a variable must pass through the variable's definition, or, in the jargon, that definitions dominate uses. This is an invariant of an SSA-style IR, that all variable uses be dominated by their associated definition.
You can flip the question around to ask what variables are available for use at a given program point, which might be read equivalently as which variables are in scope; the answer is, all definitions from all program points that dominate the use site. The "CPS" in "CPS soup" stands for continuation-passing style , a dialect of the lambda calculus, which has also has a history of use as a compiler intermediate representation. But it turns out that if we use the lambda calculus in its conventional form, we end up needing to maintain a lexical scope nesting at the same time that we maintain the control-flow graph, and the lexical scope tree can fail to reflect the dominator tree. I go into this topic in more detail in an old article, and if it interests you, please do go deep.
Compilation unit is intmap of label to cont
cont := $kargs names vars term
| ...
term := $continue k src expr
| ...
expr := $const C
| $primcall ’add #f (a b)
| ...
Conventionally, entry point is lowest-numbered label
Anyway! In Guile, the concrete form that CPS soup takes is that a program is an intmap of label to cont. A cont is the smallest labellable unit of code. You can call them blocks if that makes you feel better. One kind of cont, $kargs, binds incoming values to variables. It has a list of variables, vars , and also has an associated list of human-readable names, names , for debugging purposes.
A $kargs contains a term , which is like a control instruction. One kind of term is $continue, which passes control to a continuation k. Using our earlier language, this is just goto *k*, with values, as in MLton. (The src is a source location for the term.) The values come from the term's expr , of which there are a dozen kinds or so, for example $const which passes a literal constant, or $primcall, which invokes some kind of primitive operation, which above is add. The primcall may have an immediate operand, in this case #f, and some variables that it uses, in this case a and b. The number and type of the produced values is a property of the primcall; some are just for effect, some produce one value, some more.
term := $continue k src expr
| $branch kf kt src op param args
| $switch kf kt* src arg
| $prompt k kh src escape? tag
| $throw src op param args
Expressions can have effects, produce values
expr := $const val
| $primcall name param args
| $values args
| $call proc args
| ...
There are other kinds of terms besides $continue: there is $branch, which proceeds either to the false continuation kf or the true continuation kt depending on the result of performing op on the variables args , with immediate operand param. In our running example, we might have made the initial term via:
(build-term
($branch BB1 BB2 'false? #f (a0)))
The definition of build-term (and build-cont and build-exp) is in the (language cps) module.
There is also $switch, which takes an unboxed unsigned integer arg and performs an array dispatch to the continuations in the list kt , or kf otherwise.
There is $prompt which continues to its k , having pushed on a new continuation delimiter associated with the var tag ; if code aborts to tag before the prompt exits via an unwind primcall, the stack will be unwound and control passed to the handler continuation kh. If escape? is true, the continuation is escape-only and aborting to the prompt doesn't need to capture the suspended continuation.
Finally there is $throw, which doesn't continue at all, because it causes a non-resumable exception to be thrown. And that's it; it's just a handful of kinds of term, determined by the different shapes of control-flow (how many continuations the term has).
When it comes to values, we have about a dozen expression kinds. We saw $const and $primcall, but I want to explicitly mention $values, which simply passes on some number of values. Often a $values expression corresponds to passing an input to a phi variable, though $kargs vars can get their definitions from any expression that produces the right number of values.
Guile functions untyped, can multiple return values
Error if too few values, possibly truncate too many values, possibly cons as rest arg...
Calling convention: contract between val producer & consumer
Continuation of $call unlike that of $const
When a $continue term continues to a $kargs with a $const 42 expression, there are a number of invariants that the compiler can ensure: that the $kargs continuation is always passed the expected number of values, that the vars that it binds can be allocated to specific locations (e.g. registers), and that because all predecessors of the $kargs are known, that those predecessors can place their values directly into the variable's storage locations. Effectively, the compiler determines a custom calling convention between each $kargs and its predecessors.
Consider the $call expression, though; in general you don't know what the callee will do to produce its values. You don't even generally know that it will produce the right number of values. Therefore $call can't (in general) continue to $kargs; instead it continues to $kreceive, which expects the return values in well-known places. $kreceive will check that it is getting the right number of values and then continue to a $kargs, shuffling those values into place. A standard calling convention defines how functions return values to callers.
cont := $kfun src meta self ktail kentry
| $kclause arity kbody kalternate
| $kargs names syms term
| $kreceive arity kbody
| $ktail
$kclause, $kreceive very similar
Continue to $ktail: return
$call and return (and $throw, $prompt) exit first-order flow graph
Of course, a $call expression could be a tail-call, in which case it would continue instead to $ktail, indicating an exit from the first-order function-local control-flow graph.
The calling convention also specifies how to pass arguments to callees, and likewise those continuations have a fixed calling convention; in Guile we start functions with $kfun, which has some metadata attached, and then proceed to $kclause which bridges the boundary between the standard calling convention and the specialized graph of $kargs continuations. (Many details of this could be tweaked, for example that the case-lambda dispatch built-in to $kclause could instead dispatch to distinct functions instead of to different places in the same function; historical accidents abound.)
As a detail, if a function is well-known , in that all its callers are known, then we can lighten the calling convention, moving the argument-count check to callees. In that case $kfun continues directly to $kargs. Similarly for return values, optimizations can make $call continue to $kargs, though there is still some value-shuffling to do.
CPS bridges AST (Tree-IL) and target code
High-level: vars in outer functions in scope
Closure conversion between high and low
Low-level: Explicit closure representations; access free vars through closure
CPS soup is the bridge between parsed Scheme and machine code. It starts out quite high-level, notably allowing for nested scope, in which expressions can directly refer to free variables. Variables are small integers, and for high-level CPS, variable indices have to be unique across all functions in a program. CPS gets lowered via closure conversion, which chooses specific representations for each closure that remains after optimization. After closure conversion, all variable access is local to the function; free variables are accessed via explicit loads from a function's closure.
Optimizations before and after lowering
Some exprs only present in one level
Some high-level optimizations can merge functions (higher-order to first-order)
Because of the broad remit of CPS, the language itself has two dialects, high and low. The high level dialect has cross-function variable references, first-class abstract functions (whose representation hasn't been chosen), and recursive function binding. The low-level dialect has only specific ways to refer to functions: labels and specific closure representations. It also includes calls to function labels instead of just function values. But these are minor variations; some optimization and transformation passes can work on either dialect.
Intmap, intset: Clojure-style persistent functional data structures
Program: intmap<label,cont>
Optimization: program→program
Identify functions: (program,label)→intset<label>
Edges: intmap<label,intset<label>>
Compute succs: (program,label)→edges
Compute preds: edges→edges
I mentioned that programs were intmaps, and specifically in Guile they are Clojure/Bagwell-style persistent functional data structures. By functional I mean that intmaps (and intsets) are values that can't be mutated in place (though we do have the transient optimization).
I find that immutability has the effect of deploying a sense of calm to the compiler hacker -- I don't need to worry about data structures changing out from under me; instead I just structure all the transformations that you need to do as functions. An optimization is just a function that takes an intmap and produces another intmap. An analysis associating some data with each program label is just a function that computes an intmap, given a program; that analysis will never be invalidated by subsequent transformations, because the program to which it applies will never be mutated.
This pervasive feeling of calm allows me to tackle problems that I wouldn't have otherwise been able to fit into my head. One example is the novel online CSE pass; one day I'll either wrap that up as a paper or just capitulate and blog it instead.
A[k] = meet(A[p] for p in preds[k])
- kill[k] + gen[k]
Compute available values at labels:
intmap<label,intset<val>>intmap-intersect<intset-intersect>intset-subtract, intset-unionBut to keep it concrete, let's take the example of flow analysis. For example, you might want to compute "available values" at a given label: these are the values that are candidates for common subexpression elimination. For example if a term is dominated by a car x primcall whose value is bound to v, and there is no path from the definition of V to a subsequent car x primcall, we can replace that second duplicate operation with $values (v) instead.
There is a standard solution for this problem, which is to solve the flow equation above. I wrote about this at length ages ago, but looking back on it, the thing that pleases me is how easy it is to decompose the task of flow analysis into manageable parts, and how the types tell you exactly what you need to do. It's easy to compute an initial analysis A, easy to define your meet function when your maps and sets have built-in intersect and union operators, easy to define what addition and subtraction mean over sets, and so on.
intmap-intersect<intset-intersect>intset-subtract, intset-unionNaïve: O(nconts * nvals)
Structure-sharing: O(nconts * log(nvals))
Computing an analysis isn't free, but it is manageable in cost: the structure-sharing means that meet is usually trivial (for fallthrough control flow) and the cost of + and - is proportional to the log of the problem size.
Relatively uniform, orthogonal
Facilitates functional transformations and analyses, lowering mental load: “I just have to write a function from foo to bar; I can do that”
Encourages global optimizations
Some kinds of bugs prevented by construction (unintended shared mutable state)
We get the SSA optimization literature
Well, we're getting to the end here, and I want to take a step back. Guile has used CPS soup as its middle-end IR for about 8 years now, enough time to appreciate its fine points while also understanding its weaknesses.
On the plus side, it has what to me is a kind of low cognitive overhead, and I say that not just because I came up with it: Guile's development team is small and not particularly well-resourced, and we can't afford complicated things. The simplicity of CPS soup works well for our development process (flawed though that process may be!).
I also like how by having every variable be potentially a phi, that any optimization that we implement will be global (i.e. not local to a basic block) by default.
Perhaps best of all, we get these benefits while also being able to use the existing SSA transformation literature. Because CPS is SSA, the lessons learned in SSA (e.g. loop peeling) apply directly.
Pointer-chasing, indirection through intmaps
Heavier than basic blocks: more control-flow edges
Names bound at continuation only; phi predecessors share a name
Over-linearizes control, relative to sea-of-nodes
Overhead of re-computation of analyses
CPS soup is not without its drawbacks, though. It's not suitable for JIT compilers, because it imposes some significant constant-factor (and sometimes algorithmic) overheads. You are always indirecting through intmaps and intsets, and these data structures involve significant pointer-chasing.
Also, there are some forms of lightweight flow analysis that can be performed naturally on a graph of basic blocks without looking too much at the contents of the blocks; for example in our available variables analysis you could run it over blocks instead of individual instructions. In these cases, basic blocks themselves are an optimization, as they can reduce the size of the problem space, with corresponding reductions in time and memory use for analyses and transformations. Of course you could overlay a basic block graph on top of CPS soup, but it's not a well-worn path.
There is a little detail that not all phi predecessor values have names, since names are bound at successors (continuations). But this is a detail; if these names are important, little $values trampolines can be inserted.
Probably the main drawback as an IR is that the graph of conts in CPS soup over-linearizes the program. There are other intermediate representations that don't encode ordering constraints where there are none; perhaps it would be useful to marry CPS soup with sea-of-nodes, at least during some transformations.
Finally, CPS soup does not encourage a style of programming where an analysis is incrementally kept up to date as a program is transformed in small ways. The result is that we end up performing much redundant computation within each individual optimization pass.
CPS soup is SSA, distilled
Labels and vars are small integers
Programs map labels to conts
Conts are the smallest labellable unit of code
Conts can have terms that continue to other conts
Compilation simplifies and lowers programs
Wasm vs VM backend: a question for another day :)
But all in all, CPS soup has been good for Guile. It's just SSA by another name, in a simpler form, with a functional flavor. Or, it's just CPS, but first-order only, without lambda.
In the near future, I am interested in seeing what a new GC will do for CPS soup; will bump-pointer allocation palliate some of the costs of pointer-chasing? We'll see. A tricky thing about CPS soup is that I don't think that anyone else has tried it in other languages, so it's hard to objectively understand its characteristics independent of Guile itself.
Finally, it would be nice to engage in the academic conversation by publishing a paper somewhere; I would like to see interesting criticism, and blog posts don't really participate in the citation graph. But in the limited time available to me, faced with the choice between hacking on something and writing a paper, it's always been hacking, so far :)
Speaking of limited time, I probably need to hit publish on this one and move on. Happy hacking to all, and until next time.
Hello again!
In the last post, we briefly mentioned the with-store and run-with-store macros. Today, we'll be looking at those in further detail, along with the related monad library and the %store-monad!
Typically, we use monads to chain operations together, and the %store-monad is no different; it's used to combine operations that work on the Guix store (for instance, creating derivations, building derivations, or adding data files to the store).
However, monads are a little hard to explain, and from a distance, they seem to be quite incomprehensible. So, I want you to erase them from your mind for now. We'll come back to them later. And be aware that if you can't seem to get your head around them, it's okay; you can understand most of the architecture of Guix without understanding monads.
Let's instead implement another M of functional programming, maybe values, representing a value that may or may not exist. For instance, there could be a procedure that attempts to pop a stack, returning the result if there is one, or nothing if the stack has no elements.
maybe is a very common feature of statically-typed functional languages, and you'll see it all over the place in Haskell and OCaml code. However, Guile is dynamically typed, so we usually use ad-hoc #f values as the "null value" instead of a proper "nothing" or "none".
Just for fun, though, we'll implement a proper maybe in Guile. Fire up that REPL once again, and let's import a bunch of modules that we'll need:
(use-modules (ice-9 match)
(srfi srfi-9))
We'll implement maybe as a record with two fields, is? and value. If the value contains something, is? will be #t and value will contain the thing in question, and if it's empty, is?'ll be #f.
(define-record-type <maybe>
(make-maybe is? value)
maybe?
(is? maybe-is?)
(value maybe-value))
Now we'll define constructors for the two possible states:
(define (something value)
(make-maybe #t value))
(define (nothing)
(make-maybe #f #f)) ;the value here doesn't matter; we'll just use #f
And make some silly functions that return optional values:
(define (remove-a str)
(if (eq? (string-ref str 0) #\a)
(something (substring str 1))
(nothing)))
(define (remove-b str)
(if (eq? (string-ref str 0) #\b)
(something (substring str 1))
(nothing)))
(remove-a "ahh")
⇒ #<<maybe> is?: #t value: "hh">
(remove-a "ooh")
⇒ #<<maybe> is?: #f value: #f>
(remove-b "bad")
⇒ #<<maybe> is?: #t value: "ad">
But what if we want to compose the results of these functions?
As you might have guessed, this is not fun. Cosplaying as a compiler backend typically isn't.
(let ((t1 (remove-a "abcd")))
(if (maybe-is? t1)
(remove-b (maybe-value t1))
(nothing)))
⇒ #<<maybe> is?: #t value: "cd">
(let ((t1 (remove-a "bbcd")))
(if (maybe-is? t1)
(remove-b (maybe-value t1))
(nothing)))
⇒ #<<maybe> is?: #f value: #f>
I can almost hear the heckling. Even worse, composing three:
(let* ((t1 (remove-a "abad"))
(t2 (if (maybe-is? t1)
(remove-b (maybe-value t1))
(nothing))))
(if (maybe-is? t2)
(remove-a (maybe-value t2))
(nothing)))
⇒ #<<maybe> is?: #t value: "d">
So, how do we go about making this more bearable? Well, one way could be to make remove-a and remove-b accept maybes:
(define (remove-a ?str)
(match ?str
(($ <maybe> #t str)
(if (eq? (string-ref str 0) #\a)
(something (substring str 1))
(nothing)))
(_ (nothing))))
(define (remove-b ?str)
(match ?str
(($ <maybe> #t str)
(if (eq? (string-ref str 0) #\b)
(something (substring str 1))
(nothing)))
(_ (nothing))))
Not at all pretty, but it works!
(remove-b (remove-a (something "abc")))
⇒ #<<maybe> is?: #t value: "c">
Still, our procedures now require quite a bit of boilerplate. Might there be a better way?
>>= UsFirst of all, we'll revert to our original definitions of remove-a and remove-b, that is to say, the ones that take a regular value and return a maybe.
(define (remove-a str)
(if (eq? (string-ref str 0) #\a)
(something (substring str 1))
(nothing)))
(define (remove-b str)
(if (eq? (string-ref str 0) #\b)
(something (substring str 1))
(nothing)))
What if tried introducing higher-order procedures (procedures that accept other procedures as arguments) into the equation? Because we're functional programmers and we have an unhealthy obsession with that sort of thing.
(define (maybe-chain maybe proc)
(if (maybe-is? maybe)
(proc (maybe-value maybe))
(nothing)))
(maybe-chain (something "abc")
remove-a)
⇒ #<<maybe> is?: #t value: "bc">
(maybe-chain (nothing)
remove-a)
⇒ #<<maybe> is?: #f value: #f>
It lives! To make it easier to compose procedures like this, we'll define a macro that allows us to perform any number of sequenced operations with only one composition form:
(define-syntax maybe-chain*
(syntax-rules ()
((_ maybe proc)
(maybe-chain maybe proc))
((_ maybe proc rest ...)
(maybe-chain* (maybe-chain maybe proc)
rest ...))))
(maybe-chain* (something "abad")
remove-a
remove-b
remove-a)
⇒ #<<maybe> is?: #t value: "d">
Congratulations, you've just implemented the bind operation, commonly written as >>=, for our maybe type. And it turns out that a monad is just any container-like value for which >>= (along with another procedure called return, which wraps a given value in the simplest possible form of a monad) has been implemented.
A more formal definition would be that a monad is a mathematical object composed of three parts: a type, a bind function, and a return function. So, how do monads relate to Guix?
Now that we've reinvented the wheel, we'd better learn to use the original wheel. Guix provides a generic, high-level monads library, along with the two generic monads %identity-monad and %state-monad, and the Guix-specific %store-monad. Since maybe is not one of them, let's integrate our version into the Guix monad system!
First we'll import the module that provides the aforementioned library:
(use-modules (guix monads))
To define a monad's behaviour in Guix, we simply use the define-monad macro, and provide two procedures: bind, and return.
(define-monad %maybe-monad
(bind maybe-chain)
(return something))
bind is just the procedure that we use to compose monadic procedure calls together, and return is the procedure that wraps values in the most basic form of the monad. A properly implemented bind and return must follow the so-called monad laws :
(bind (return x) proc) must be equivalent to (proc x).(bind monad return) must be equivalent to just monad.(bind (bind monad proc-1) proc-2) must be equivalent to (bind monad (lambda (x) (bind (proc-1 x) proc-2))).Let's verify that our maybe-chain and something procedures adhere to the monad laws:
(define (mlaws-proc-1 x)
(something (+ x 1)))
(define (mlaws-proc-2 x)
(something (+ x 2)))
;; First law: the left identity.
(equal? (maybe-chain (something 0)
mlaws-proc-1)
(mlaws-proc-1 0))
⇒ #t
;; Second law: the right identity.
(equal? (maybe-chain (something 0)
something)
(something 0))
⇒ #t
;; Third law: associativity.
(equal? (maybe-chain (maybe-chain (something 0)
mlaws-proc-1)
mlaws-proc-2)
(maybe-chain (something 0)
(lambda (x)
(maybe-chain (mlaws-proc-1 x)
mlaws-proc-2))))
⇒ #t
Now that we know they're valid, we can use the with-monad macro to tell Guix to use these specific implementations of bind and return, and the >>= macro to thread monads through procedure calls!
(with-monad %maybe-monad
(>>= (something "aabbc")
remove-a
remove-a
remove-b
remove-b))
⇒ #<<maybe> is?: #t value: "c">
We can also now use return:
(with-monad %maybe-monad
(return 32))
⇒ #<<maybe> is?: #t value: 32>
But Guix provides many higher-level interfaces than >>= and return, as we will see. There's mbegin, which evaluates monadic expressions without binding them to symbols, returning the last one. This, however, isn't particularly useful with our %maybe-monad, as it's only really usable if the monadic operations within have side effects, just like the non-monadic begin.
There's also mlet and mlet*, which do bind the results of monadic expressions to symbols, and are essentially equivalent to a chain of (>>= MEXPR (lambda (BINDING) ...)):
;; This is equivalent...
(mlet* %maybe-monad ((str -> "abad") ;non-monadic binding uses the -> symbol
(str1 (remove-a str))
(str2 (remove-b str)))
(remove-a str))
⇒ #<<maybe> is?: #t value: "d">
;; ...to this:
(with-monad %maybe-monad
(>>= (return "abad")
(lambda (str)
(remove-a str))
(lambda (str1)
(remove-b str))
(lambda (str2)
(remove-a str))))
Various abstractions over these two exist too, such as mwhen (a when plus an mbegin), munless (an unless plus an mbegin), and mparameterize (dynamically-scoped value rebinding, like parameterize, in a monadic context). lift takes a procedure and a monad and creates a new procedure that returns a monadic value.
There are also interfaces for manipulating lists wrapped in monads; listm creates such a list, sequence turns a list of monads into a list wrapped in a monad, and the anym, mapm, and foldm procedures are like their non-monadic equivalents, except that they return lists wrapped in monads.
This is all well and good, you may be thinking, but why does Guix need a monad library, anyway? The answer is technically that it doesn't. But building on the monad API makes a lot of things much easier, and to learn why, we're going to look at one of Guix's built-in monads.
Guix implements a monad called %state-monad, and it works with single-argument procedures returning two values. Behold:
(with-monad %state-monad
(return 33))
⇒ #<procedure 21dc9a0 at <unknown port>:1106:22 (state)>
The run-with-state value turns this procedure into an actually useful value, or, rather, two values:
(run-with-state (with-monad %state-monad (return 33))
(list "foo" "bar" "baz"))
⇒ 33
⇒ ("foo" "bar" "baz")
What can this actually do for us, though? Well, it gets interesting if we do some >>=ing:
(define state-seq
(mlet* %state-monad ((number (return 33)))
(state-push number)))
result
⇒ #<procedure 7fcb6f466960 at <unknown port>:1484:24 (state)>
(run-with-state state-seq (list 32))
⇒ (32)
⇒ (33 32)
(run-with-state state-seq (list 30 99))
⇒ (30 99)
⇒ (33 30 99)
What is state-push? It's a monadic procedure for %state-monad that takes whatever's currently in the first value (the primary value) and pushes it onto the second value (the state value), which is assumed to be a list, returning the old state value as the primary value and the new list as the state value.
So, when we do (run-with-state result (list 32)), we're passing (list 32) as the initial state value, and then the >>= form passes that and 33 to state-push. What %state-monad allows us to do is thread together some procedures that require some kind of state, while essentially pretending the state value is stored globally, like you might do in, say, C, and then retrieve both the final state and the result at the end!
If you're a bit confused, don't worry. We'll write some of our own %state-monad-based monadic procedures and hopefully all will become clear. Consider, for instance, the Fibonacci sequence, in which each value is computed by adding the previous two. We could use the %state-monad to compute Fibonacci numbers by storing the previous number as the primary value and the number before that as the state value:
(define (fibonacci-thing value)
(lambda (state)
(values (+ value state)
value)))
Now we can feed our Fibonacci-generating procedure the first value using run-with-state and the second using return:
(run-with-state
(mlet* %state-monad ((starting (return 1))
(n1 (fibonacci-thing starting))
(n2 (fibonacci-thing n1)))
(fibonacci-thing n2))
0)
⇒ 3
⇒ 2
(run-with-state
(mlet* %state-monad ((starting (return 1))
(n1 (fibonacci-thing starting))
(n2 (fibonacci-thing n1))
(n3 (fibonacci-thing n2))
(n4 (fibonacci-thing n3))
(n5 (fibonacci-thing n4)))
(fibonacci-thing n5))
0)
⇒ 13
⇒ 8
This is all very nifty, and possibly useful in general, but what does this have to do with Guix? Well, many Guix store-based operations are meant to be used in concert with yet another monad, called the %store-monad. But if we look at (guix store), where %store-monad is defined...
(define-alias %store-monad %state-monad)
(define-alias store-return state-return)
(define-alias store-bind state-bind)
It was all a shallow façade! All the "store monad" is is a special case of the state monad, where a value representing the store is passed as the state value.
We mentioned that, technically, we didn't need monads for Guix. Indeed, many (now deprecated) procedures take a store value as the argument, such as build-expression->derivation. However, monads are far more elegant and simplify store code by quite a bit.
build-expression->derivation, being deprecated, should never of course be used. For one thing, it uses the "quoted build expression" style, rather than G-expressions (we'll discuss gexps another time). The best way to create a derivation from some basic build code is to use the new-fangled gexp->derivation procedure:
(use-modules (guix gexp)
(gnu packages irc))
(define symlink-irssi
(gexp->derivation "link-to-irssi"
#~(symlink #$(file-append irssi "/bin/irssi") #$output)))
⇒ #<procedure 7fddcc7b81e0 at guix/gexp.scm:1180:2 (state)>
You don't have to understand the #~(...) form yet, only everything surrounding it. We can see that this gexp->derivation returns a procedure taking the initial state (store), just like our %state-monad procedures did, and like we used run-with-state to pass the initial state to a %state-monad monadic value, we use our old friend run-with-store when we have a %store-monad monadic value!
(define symlink-irssi-drv
(with-store store
(run-with-store store
symlink-irssi)))
⇒ #<derivation /gnu/store/q7kwwl4z6psifnv4di1p1kpvlx06fmyq-link-to-irssi.drv => /gnu/store/6a94niigx4ii0ldjdy33wx9anhifr25x-link-to-irssi 7fddb7ef52d0>
Let's just check this derivation is as expected by reading the code from the builder script.
(define symlink-irssi-builder
(list-ref (derivation-builder-arguments symlink-irssi-drv) 1))
(call-with-input-file symlink-irssi-builder
(lambda (port)
(read port)))
⇒ (symlink
"/gnu/store/hrlmypx1lrdjlxpkqy88bfrzg5p0bn6d-irssi-1.4.3/bin/irssi"
((@ (guile) getenv) "out"))
And indeed, it symlinks the irssi binary to the output path. Some other, higher-level, monadic procedures include interned-file, which copies a file from outside the store into it, and text-file, which copies some text into it. Generally, these procedures aren't used, as there are higher-level procedures that perform similar functions (which we will discuss later), but for the sake of this blog post, here's an example:
(with-store store
(run-with-store store
(text-file "unmatched-paren"
"( <paren@disroot.org>")))
⇒ "/gnu/store/v6smacxvdk4yvaa3s3wmd54lixn1dp3y-unmatched-paren"
What have we learned about monads? The key points we can take away are:
maybe values.(guix monads) module provides the state monad, which allows you to thread state through procedures, allowing you to essentially pretend it's a global variable that's modified by each procedure.If you've read this post in its entirety but still don't yet quite get it, don't worry. Try to modify and tinker about with the examples, and ask any questions on the IRC channel #guix:libera.chat and mailing list at help-guix@gnu.org, and hopefully it will all click eventually!
GNU Guix is a transactional package manager and an advanced distribution of the GNU system that respects user freedom. Guix can be used on top of any system running the Hurd or the Linux kernel, or it can be used as a standalone operating system distribution for i686, x86_64, ARMv7, AArch64 and POWER9 machines.
In addition to standard package management features, Guix supports transactional upgrades and roll-backs, unprivileged package management, per-user profiles, and garbage collection. When used as a standalone GNU/Linux distribution, Guix offers a declarative, stateless approach to operating system configuration management. Guix is highly customizable and hackable through Guile programming interfaces and extensions to the Scheme language.
Die reihenweise abgeschalteten #Atomkraftwerke in #F kommen ja eher so auf Seite 2 zu liegen.
ich freue mich schon auf die #Schlagzeile, wenn in den nächsten Tagen ein #Windrad wegen #Überhitzung in Brand gerät.
Hello, I use #Guile #Scheme implementation, and I'd like to know how do you do to get the terminal width (to store in a variable for example)?
After tried with getenv procedure:
(getenv "COLUMNS")
That return #f (unless export COLUMNS=$(tput cols) either in .bashrc or in the guile shebang's script)
#!/usr/bin/env sh
exec env COLUMNS=$(tput cols) guile -s "$0"
!#
But using this, if you resize the terminal, the value is not updated.
So I have to use:
```
(use-modules (ice-9 popen))
(use-modules (ice-9 rdelim))
(define (get-terminal-width)
(let* ([port (open-input-pipe "tput cols")]
[terminal-width (read-line port)])
(close-pipe port)
terminal-width))
May be someone has a more efficient way to get the terminal width, thanks.
#GNUser #Guile #lisp #Scheme #programming
Making cross-cutting changes over a large code base is difficult, but it's occasionally necessary if we are to keep the code base tidy and malleable. With almost 800K source lines of code, Guix can reasonably be called a large code base. One might argue that almost 80% of this code is package definitions, which “doesn't count”. Reality is that it does count, not only because those package definitions are regular Scheme code, but also they are directly affected by the big change Guix has just undergone.
This post looks at what’s probably the biggest change Guix has seen since it started nine years ago and that anyone writing packages will immediately notice: simplified package inputs. Yes, we just changed how each of the 20K packages plus those in third-party channels can declare their dependencies. Before describing the change, how we implemented it, and how packagers can adapt, let’s first take a look at the previous situation and earlier improvements that made this big change possible.
Packages in Guix are defined using a domain-specific language embedded in the Scheme programming language—an EDSL, for the programming language geeks among us. This is a departure from other designs such as that of Nix, which comes with a dedicated language, and it gives packagers and users access to a rich programming interface while retaining the purely declarative style of package definitions.
This package EDSL is one of the oldest bits of Guix and was described in a 2013 paper. Although embedded in Scheme, the package “language” was designed to be understandable by people who’ve never practiced any kind of Lisp before—you could think of it as a parenthesized syntax for JSON or XML. It’s reasonable to say that it’s been successful at that: of the 600+ people who contributed to Guix over the years, most had never written Scheme or Lisp before. The example given in that paper remains a valid package definition:
(define hello
(package
(name "hello")
(version "2.8")
(source (origin
(method url-fetch)
(uri (string-append "mirror://gnu/hello/hello-"
version ".tar.gz"))
(sha256 (base32 "0wqd8..."))))
(build-system gnu-build-system)
(arguments
'(#:configure-flags
`("--disable-color"
,(string-append "--with-gawk="
(assoc-ref %build-inputs "gawk")))))
(inputs `(("gawk" ,gawk)))
(synopsis "GNU Hello")
(description "An illustration of GNU's engineering practices.")
(home-page "http://www.gnu.org/software/hello/")
(license gpl3+)))
Of particular interest here is the inputs field, which lists build-time dependencies. Here there’s only one, GNU Awk; it has an associated label , "gawk". The ,gawk bit lets us insert the value of the gawk variable, which is another package. We can list more dependencies like so:
(inputs `(("gawk" ,gawk)
("gettext" ,gnu-gettext)
("pkg-config" ,pkg-config)))
Quite a bit of boilerplate. Unless you’re into Lisp, this probably looks weird to you—manageable, but weird. What’s the deal with this backquote and those commas? The backquote is shorthand for quasiquote and commas are shorthand for unquote; it’s a facility that Lisp and Scheme provide to construct lists.
Lispers couldn’t live without quasiquote, it’s wonderful. Still, exposing newcomers to this syntax has always been uncomfortable; in tutorials you’d end up saying “yeah don’t worry, just write it this way”. Our goal though is to empower users by giving them abstractions they can comprehend, hopefully providing a smooth path towards programming without noticing. This seemingly opaque backquote-string-unquote construct works against that goal.
Then, you ask, why did Guix adopt this unpleasant syntax for inputs in the first place? Input syntax had to satisfy one requirement: that it’d be possible for “build-side code” to refer to a specific input. And what’s build-side code? It’s code that appears in the package definition that is staged for later execution—code that’s only evaluated when the package is actually built. The bit that follows #:configure-flags in the example above is build-side code: it’s an expression evaluated if and when the package gets built. That #:configure-flags expression refers to the gawk package to construct a flag like "--with-gawk=/gnu/store/…-gawk-5.0.1"; it does so by referring to the special %build-inputs variable, which happens to contain an association list that maps input labels to file names. The "gawk" label in inputs is here to allow build-side code to get at an input’s file name.
Still here? The paragraphs above are a demonstration of the shortcoming of this approach. That we have to explain so much suggests we’re lacking an abstraction that would make the whole pattern clearer.
The missing abstraction came to Guix a couple of years later: G-expressions. Without going into the details, which were covered elsewhere, notably in a research article, g-expressions, or “gexps”, are traditional Lisp s-expressions (“sexps”) on steroids. A gexp can contain a package record or any other “file-like object” and, when that gexp is serialized for eventual execution, the package is replaced by its /gnu/store/… file name.
Gexps have been used since 2014–2015 in all of Guix System and they’ve been great to work with, but package definitions were stuck with old-style sexps. One reason is that a big chunk of the code that deals with packages and build systems had to be ported to the gexp-related programming interfaces; a first attempt had been made long ago but performance was not on par with that of the old code, so postponing until that was addressed seemed wiser. The second reason was that using gexps in package definitions could be so convenient that packagers might unwillingly find themselves creating inconsistent packages.
We can now rewrite our hello package such that configure flags are expressed using a gexp:
(define hello
(package
(name "hello")
;; …
(arguments
(list #:configure-flags
#~`("--disable-color"
,(string-append "--with-gawk=" #$gawk))))
(inputs `(("gawk" ,gawk)))))
The reference inserted here with #$gawk (#$ is synonymous for ungexp, the gexp equivalent of traditional unquote) refers to the global gawk variable. This is more concise and semantically clearer than the (assoc-ref %build-inputs "gawk") snippet we had before.
Now suppose you define a package variant using this common idiom:
(define hello-variant
(package
(inherit hello)
(name "hello-variant")
(inputs `(("gawk" ,gawk-4.0)))))
Here the intent is to create a package that depends on a different version of GNU Awk—the hypothetical gawk-4.0 instead of gawk. However, the #:configure-flags gexp of this variant still refers to the gawk variable, contrary to what the inputs field prescribes; in effect, this variant depends on the two Awk versions.
To address this discrepancy, we needed a new linguistic device , to put it in a fancy way. It arrived in 2019 in the form of self-referential records. Within a field such as the arguments field above, it’s now possible to refer to this-package to get at the value of the package being defined. (If you’ve done object-oriented programming before, you might be thinking that we just rediscovered the this or self pointer, and there’s some truth in it. :-)) With a bit of syntactic sugar, we can rewrite the example above so that it refers to the Awk package that appears in its own inputs field:
(define hello
(package
(name "hello")
;; …
(arguments
(list #:configure-flags
#~(list (string-append "--with-gawk="
#$(this-package-input "gawk")))))
(inputs `(("gawk" ,gawk)))))
With this in place, we can take advantage of gexps in package definitions while still supporting the common idiom to define package variants, wheee!
That was a long digression from our input label theme but, as you can see, all this interacts fairly tightly.
Now that we have gexps and self-referential records, it looks like we can finally get rid of input labels: they’re no longer strictly necessary because we can insert packages in gexps instead of looking them up by label in build-side code. We “just” need to devise a backward compatibility plan…
Input labels are pervasive; they’re visible in three contexts:
inputs fields of package definitions;inputs keyword parameter of build phases;package-inputs and related functions are expected to return a list of labeled inputs.We’re brave but not completely crazy, so we chose to focus on #1 for now—it’s also the most visible of all three—, with an plan to incrementally address #2, leaving #3 for later.
To allow for label-less inputs, we augmented the record interface with field sanitizers. This feature allows us to define a procedure that inspects and transforms the value specified for the inputs, native-inputs, and propagated-inputs. Currently that procedure reintroduces input labels when they’re missing. In a sense, we’re just changing the surface syntax but under the hood everything is unchanged. With this change, our example above can now be written like this:
(define hello
(package
(name "hello")
;; …
(inputs (list gawk))))
Much nicer, no? The effect is even more pleasant for packages with a number of inputs:
(define-public guile-sqlite3
(package
(name "guile-sqlite3")
;; …
(build-system gnu-build-system)
(native-inputs (list autoconf automake guile-3.0 pkg-config))
(inputs (list guile-3.0 sqlite))))
That’s enough to spark joy to anyone who’s taught the previous syntax. Currently this is transformed into something like:
(define-public guile-sqlite3
(package
;; …
(native-inputs
(map add-input-label
(list autoconf automake guile-3.0 pkg-config)))))
… where the add-input-label function turns a package into a label/package pair. It does add a little bit of run-time overhead, but nothing really measurable.
There are also cases where package definitions, in particular for package variants, would directly manipulate input lists as returned by package-inputs and related procedures. It’s a case where packagers had to be aware of input labels, and they would typically use association list (or “alist”) manipulation procedures and similar construct—this is context #3 above. To replace those idioms, we defined a higher-level construct that does not assume input labels. For example, a common idiom when defining a package variant with additional dependencies goes like this:
(define hello-with-additional-dependencies
(package
(inherit hello)
(name "hello-with-bells-and-whistles")
(inputs `(("guile" ,guile-3.0)
("libtextstyle" ,libtextstyle)
,@(package-inputs hello)))))
The variant defined above adds two inputs to those of hello. We introduced a macro, modify-inputs, which allows packagers to express that in a higher-level (and less cryptic) fashion, in a way that does not refer to input labels. Using this other linguistic device (ha ha!), the snippet above becomes:
(define hello-with-additional-dependencies
(package
(inherit hello)
(name "hello-with-bells-and-whistles")
(inputs (modify-inputs (package-inputs hello)
(prepend guile-3.0 libtextstyle)))))
Similarly, modify-inputs advantageously subsumes alist-delete and whatnot when willing to replace or remove inputs, like so:
(modify-inputs (package-inputs hello)
(replace "gawk" my-special-gawk)
(delete "guile"))
On the build side—context #2 above—, we also provide new procedures that allow packagers to avoid relying on input labels: search-input-file and search-input-directory. Instead of having build phases that run code like:
(lambda* (#:key inputs #:allow-other-keys)
;; Replace references to “/sbin/ip” by references to
;; the actual “ip” command in /gnu/store.
(substitute* "client/scripts/linux"
(("/sbin/ip")
;; Look up the input labeled “iproute”.
(string-append (assoc-ref inputs "iproute")
"/sbin/ip"))))
… you’d now write:
(lambda* (#:key inputs #:allow-other-keys)
;; Replace references to “/sbin/ip” by references to
;; the actual “ip” command in /gnu/store.
(substitute* "client/scripts/linux"
(("/sbin/ip")
;; Search “/sbin/ip” among all the inputs.
(search-input-file inputs "/sbin/ip"))))
Nothing revolutionary but a couple of advantages: code is no longer tied to input labels or package names, and search-input-file raises an exception when the file is not found, which is better than building an incorrect file name.
That was a deep dive into packaging! If you’re already packaging software for Guix, you hopefully see how to do things “the new way”. Either way, it’s interesting to see the wide-ranging implications of what initially looks like a simple change. Things get complex when you have to consider all the idioms that 20,000 packages make use of.
It’s nice to have a plan to change the style of package definitions, but how do you make it happen concretely? The last thing we want is, for the next five years, to have to explain two package styles to newcomers instead of one.
First, guix import now returns packages in the new style. But what about existing package definitions?
Fortunately, most of the changes above can be automated: that’s the job of the guix style command that we added for this purpose, but which may eventually be extended to make package definitions prettier in all sorts of ways. From a checkout, one can run:
./pre-inst-env guix style
Whenever it can be done safely, package inputs in every package definition are rewritten to the new style: removing input labels, and using modify-inputs where appropriate. If you maintain your own channel, you can also run it for your packages:
guix style -L /path/to/channel my-package1 my-package2 …
We recommend waiting until the next Guix release is out though, which could be a month from now, so that your channel remains usable by those who pinned an older revision of the guix channel.
We ran guix style a couple of days ago on the whole repository, leading to the biggest commit in Guix history:
460 files changed, 37699 insertions(+), 49782 deletions(-)
Woohoo! Less than 15% of the packages (not counting Rust packages, which are a bit special) have yet to be adjusted. In most cases, package inputs that were left unchanged are either those where we cannot automatically determine whether the change would break the package, for instance because build-side code expects certain labels, and those that are “complex”—e.g., inputs that include conditionals.
The key challenge here was making sure guix style transformations are correct; by default, we even want to be sure that changes introduced by guix style do not trigger a rebuild—that package derivations are unchanged.
To achieve that, guix style correlates the source code of each package definition with the corresponding live package record. That allows it to answer questions such as “is this label the name of the input package”. That way, it can tell that, say:
(inputs `(("libx11" ,libx11)
("libxcb" ,libxcb)))
can be rewritten without introducing a rebuild, because labels match actual package names, whereas something like this cannot, due to label mismatches:
(inputs `(("libX11" ,libx11)
("xcb" ,libxcb)))
guix style can also determine situations where changes would trigger a rebuild but would still be “safe”—without any observable effect. You can force it to make such changes by running:
guix style --input-simplification=safe
Because we’re all nitpicky when it comes to code formatting, guix style had to produce nicely formatted code, and to make local changes as opposed to rewriting complete package definitions. Lisps are famous for being homoiconic, which comes in handy in such a situation.
But the tools are our disposal are not capable enough for this application. First, Scheme’s standard read procedure, which reads an sexp (or an abstract syntax tree if you will) from a byte stream and returns it, does not preserve comments. Obviously we’d rather not throw away comments, so we came up with our own read variant that preserves comments. Similarly, we have a custom pretty printer that can write comments, allowing it to achieve changes like this:
@@ -2749,18 +2707,17 @@ (define-public debops
"debops-debops-defaults-fall-back-to-less.patch"))))
(build-system python-build-system)
(native-inputs
- `(("git" ,git)))
+ (list git))
(inputs
- `(("ansible" ,ansible)
- ("encfs" ,encfs)
- ("fuse" ,fuse)
- ("util-linux" ,util-linux) ;for umount
- ("findutils" ,findutils)
- ("gnupg" ,gnupg)
- ("which" ,which)))
+ (list ansible
+ encfs
+ fuse
+ util-linux ;for umount
+ findutils
+ gnupg
+ which))
(propagated-inputs
- `(("python-future" ,python-future)
- ("python-distro" ,python-distro)))
+ (list python-future python-distro))
(arguments
`(#:tests? #f
The pretty printer also has special rules for input lists. For instance, lists of five inputs or less go into a single line, if possible, whereas longer lists end up with one input per line, which is often more convenient, especially when visualizing diffs. It also has rules to format modify-inputs in the same way we’d do it in Emacs:
@@ -171,9 +170,9 @@ (define-public arcan-sdl
(inherit arcan)
(name "arcan-sdl")
(inputs
- `(("sdl" ,sdl)
- ,@(fold alist-delete (package-inputs arcan)
- '("libdrm"))))
+ (modify-inputs (package-inputs arcan)
+ (delete "libdrm")
+ (prepend sdl)))
(arguments
Overall that makes guix style a pretty fun meta-project!
There are several lessons here. One is that having an embedded domain-specific language is what makes such changes possible: yes package definitions have a declarative field, but we do not hide the fact that their meaning is determined by the broader Guix framework, starting with the (guix packages) module, which defines the package record type and associated procedures. Having a single repository containing both package definitions and “the package manager” is also a key enabler; we can change the framework, add new linguistic tools, and adjust package definitions at the same time. This is in contrast, for instance, with the approach taken by Nix, where the language implementation lives separately from the package collection.
Another one is that a strong, consistent community leads to consistent changes—not surprisingly in fact. It’s a pleasure to see that we, collectively, can undertake such overarching changes and all look in the same direction.
The last lesson is in how we approach design issues in a project that is now a little more than nine years old. Over these nine years it’s clear that we have usually favored “the right thing” in our design—but not at any cost. This whole change is an illustration of this. It was clear from the early days of Guix that input labels and the associated machinery were suboptimal. But it took us a few years to design an implement the missing pieces: G-expressions, self-referential records, and the various idioms that allow package definitions to benefit from these. In the meantime, we built a complete system and a community and we gained experience. We cannot claim we attained the right thing, if such a thing exists, but certainly package definitions today are closer to the declarative ideal and easier to teach.
This big change, along with countless other improvements and package upgrades, is just one guix pull away! After months of development, we have just merged the “core updates” branch bringing so many new things—from GNOME 41, to GCC 10 by default, to hardened Python packages and improved executable startup times. This paves the way for the upcoming release, most likely labeled “1.4”, unless a closer review of the changes that have landed leads us to think “2.0” would be more appropriate… Stay tuned!
GNU Guix is a transactional package manager and an advanced distribution of the GNU system that respects user freedom. Guix can be used on top of any system running the Hurd or the Linux kernel, or it can be used as a standalone operating system distribution for i686, x86_64, ARMv7, AArch64 and POWER9 machines.
In addition to standard package management features, Guix supports transactional upgrades and roll-backs, unprivileged package management, per-user profiles, and garbage collection. When used as a standalone GNU/Linux distribution, Guix offers a declarative, stateless approach to operating system configuration management. Guix is highly customizable and hackable through Guile programming interfaces and extensions to the Scheme language.

🐦💛📷24․10․2021 #TeamSintti #animals #wildlife #luonto #nature #syksy #autumn #Suomi #Jyväskylä #F/inland #talitiainen #greattit #parusmajor

bin ein bisschen hinterher, also hier noch ein schnellgekritzelter flamingo ^^
#AnimalAlphabets #drawing #watercolor #wai #zeugs #mywork #cc-by


