Dust in my eye
...In 2014, Facebook filed a patent application for a technique that employs smartphone data to figure out if two people might know each other. The author, an engineering manager at Facebook named Ben Chen, wrote that it was not merely possible to detect that two smartphones were in the same place at the same time, but that by comparing the accelerometer and gyroscope readings of each phone, the data could identify when people were facing each other or walking together. That way, Facebook could suggest you friend the person you were talking to at a bar last night, and not all the other people there that you chose not to talk to....
Not just dust.
Not just Facebook.
#33bits
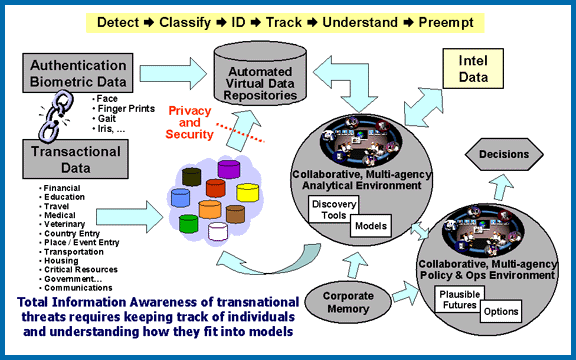
A critical point about social media -- or any public or trackable posting of data, is that it leaves identifiers which can be traced back. And these are creating records which are accessible and can be processed at rates and volumes never previously possible. It is a new "data physics". The rules of the universe have changed.
I've long been aware of persistent identifiers -- the pattern of yellow dots that colour laser printers leave, as an example (Whistleblower Reality Winner was caught based on this, due to copies of documents shared with the NSA and posted online by The Intercept), or the patterns of dead pixels in most digital cameras. There are reasons I not only don't post photos of myself but photos from my camera. But even similar patterns of dust on lenses -- an ephemeral identifier -- can be used to match up devices. As can location and timing data, gait data, and more, available from the gyroscopes which let you play pinball or tilt-ball games on your smartphone or tablet.
Or facial recognition of faces in crowds. A Hacker News commenter notes that he and his current partner turned out to have both been in a photo taken at a march before they met, which was auto-tagged after they'd followed one another online.
With 7.3 billion people in the world, all it takes are 33 bits of distinct identifying information. That can come from all kinds of sources, but location, purchase data, facial recognition, device "fingerprints" (ranging from specifically-encoded UUIDs to incidental patterns such as described here) are often sufficient. And centralised systems create repositories from which a tremendous number of such patterns can be sorted, sifted, and matched automatically.
I'm not sure how future options, including distributed and decentralised systems, will change this. But it's something I'm very much keeping in mind.
It's not about Facebook
It's not about Facebook. It's not about whether Facebook does or doesn't do this, or will or won't in the future. It's that the nature of online discussion creates highly persistent, highly detailed, not very apparent to the user data trails that can be used to draw all kinds of connections and inferences between people.
Many, many years ago, when the Web was young, and I was only slightly old, I went on an outing with some friends. We'd had a guide who had a slightly unusual name, linked to a cultural reference, and who mentioned that they'd transferred from one uni to another. I did not remember the name offhand or a last name.
But with that information, in about 20 minutes, I was able to narrow down the list of possibilities to a single person based on the then-prevalent practice of unis of listing student rosters online, as well as track down parents, hometown, and other information.
It's one of a few bits of sleuthing I've done over the years, others have have started from more or less information, produced more or less detail, sometimes been successful, sometimes not. But here was 33 bits of information captured in three pieces of data.
Today there's often a bit more of a shell wrapped around some aspects of this, but with either a very little bit of privileged access (a PI's licence, access to a skip-tracing database, Lexis-Nexis, etc.), there is all kinds of information online. Financial, legal, and other records similarly.
It's not that none of this data existed before. Some did. But it was buried in paper files, or microfiche, and you had to log road or air miles traveling to remote outposts to gather it (or pay someone to do so). And a huge amount of the information simply did not exist. (Though bits did: AT&T's comprehensive calling data files dating to the 1980s.)
I'm still not sure what to make of the difference between having information and knowing it. Trivial case in point -- I'd been looking for information on historical Usenet populations and usage, and discovered that that had been sitting in the pages of a book within a metre of my head for much of the past decade -- John S. Quarterman, The Matrix. I had the information but I didn't know it.
And that's for an individual. How much "knowledge" does an institution have? How many cases do the 13,000 agents of the FBI manage, how many suspects do they "know"? Is the information that they hold knowledge, or does it simply become material to be used as an investigation opens. Either because there is an actual crime in process, or because it's become politically expedient (or of personal interest to some agent) to do so?
Or the NSA, CIA, GRU, MI5/MI6, the Chinese or Indian or Israeli information ministries, etc., etc.
And what of AI. What is the real awareness and subject-knowledge of these systems? How rapidly can they identify individuals within crowds, say? (Some of the demos I've seen are frightening, though they may also be optimistic. Or not.)
And what happens when these capabilities are weaponised. We've seen this happen to online media. There are projections of this happening to weapons systems. What of misdemeanor police enforcement (Chinese healthcare CEO busted for jaywalking as an headshot on a bus advert is registered by a street-based facial-recognition camera), or automated lawsuit filings, or weaponised AI-driven adversarial political research and online media campaign activities in the 2020 election cycle? Drug lords, business empires, white nationalists, whatevvah.
Because that day's very nearly on us if not already here.
#data #surveillance #surveillanceCapitalism #privacy #panopticon #NotJustFacebook #dust #identity #identification
https://gizmodo.com/facebook-knows-how-to-track-you-using-the-dust-on-your-1821030620