Si vous lisez des Ebooks, voici un excellent site. On y trouve presque tout, sans inscription et gratuitement :
https://fourtoutici.click/index.php
#epub
Epub Ebook "Radikale Aufklärung - Eine Welt der offenen Quellen" Epub Ebook
Ebook –> Deutsch ONLINE LESEN –> HIER!
FREE DOWNLOAD –> HIER!

#ebook #epub #freeassange #freebook #freelibary #radikaleaufklaerung #shaitan #shaitantaschenbuch
Originally posted at: https://word.undead-network.de/2022/11/21/epub-ebook-radikale-aufklaerung-eine-welt-der-offenen-quellen-epub-ebook/
One person like that

3 Likes
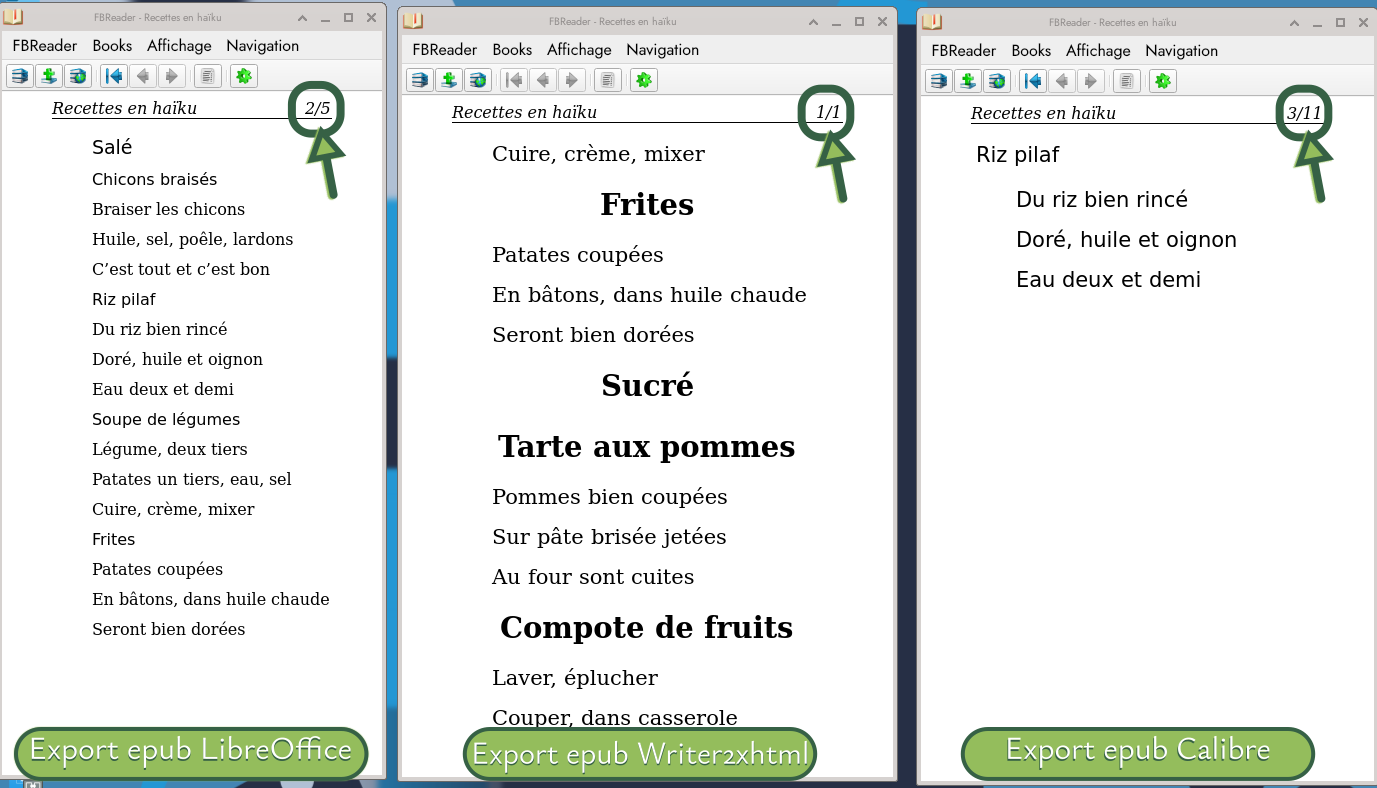
Quels outils utiliser pour générer des fichiers #EPUB pour des livres numériques ? C’est orienté #Linux (forcément) mais ça peut le faire aussi pour les autres systèmes. Des trois logiciels que j'ai testé, c'est l'extension pour #LibreOffice, #Writer2xhtml, qui s'en sort le mieux, ensuite #Calibre.
https://dutailly.net/generer-des-fichiers-epub-avec-des-logiciels-libres-et-linux
À compléter avec ce journal sur #LinuxFr où, dans les commentaires, le test a été aussi fait avec #Pandoc (qui ne s'en sort pas si bien en fait).
https://linuxfr.org/users/ysabeau/journaux/plouf-plouf-plouf-c-est-toi-qui-fera-mieux-de-l-epub
1 Shares
Ce document a été initié avec MS-WORD puis compléter avec LibreOffice afin de démontrer l’interopérabilité des systèmes.
L’objectif de ce document est d’être à la fois l’explication du sujet et un élément de réalisation des tests. La première partie est consacrée aux explications du concept, la seconde au support de tests.
Quelques explications
Les principaux outils de rédactions de textes bureautiques tels que MS-Word ou LibreOffice utilisent un format basé sur un schéma XML (Open Document pour le monde libre et LibreOffice – fichiers ODF – et Open Office XML pour la solution propriétaire de Microsoft – fichiers DOCX). Quel que soit le format choisi, la passerelle entre les deux est simple et élégante. Nous sommes loin des sauvegardes sous forme binaire.
L’accès au contenu est évident puisque ces différents formats sont des compressions au format ZIP de l’arborescence des dossiers et des fichiers, du contenu et des propriétés du contenu. C’est l’ensemble contenu + propriétés + habillage graphique qui est nommé document.
Le premier intérêt de ces formats et de ces fichiers est leur facilité de lecture. Nous sommes dans le cadre fichiers accessibles et lisibles directement et simplement sans interprétation.
Le second intérêt vient du choix d’une structure XML. Ce choix signifie que nous travaillons avec des contenus qui sont par définition structurés et ainsi faciles à traiter ou à analyser. Mais, cela cache une autre caractéristique fondamentale : la séparation stricte du fond et de la forme. Nous ne sommes pas en présence d’un amas de décorations typographiques ou positionnement spatiaux de textes (comme dans le cas du format descriptif PDF – Portable Document Format) mais bien dans un contenu structuré.
La structure de ces contenus n’est pas le fruit du hasard ou de l’application technique d’un schéma XML, c’est simplement l’expression des styles utilisés au travers des interfaces utilisateurs. L’ensemble de la chaîne, du rédacteur au stockage technique, est donc directe et élégante.
Ne reste plus qu’à définir un modèle de document (donc un modèle de structure documentaire) qui fasse sens pour les rédacteurs et les lecteurs. Ce modèle documentaire va ainsi apporter une structure sémantique au contenu en complément de la structure technique directement issue du format XML.
Mais en quoi tout ceci permet-il de proposer (voire garantir) un contenu in fine accessible et utilisable sur l’ensemble des canaux pour la bonne distribution du contenu ?
En premier lieu, l’utilisation de styles prédéfinis dans un modèle de document (et en verrouillant les styles) contraint de manière évidente le rédacteur à ne plus utiliser son outil de traitement de texte comme une simple machine à écrire (avec du simple texte décoré afin de reproduire une pseudo structure du contenu) mais, comme un outil de contenu sémantique. En effet, si l’utilisateur refuse d’utiliser les styles mis à sa disposition, le résultat à la diffusion du contenu ne serait d’une longue chaîne de caractères sans aucune structure ni indication sémantique. La séparation du fond et de la forme entraîne de fait un non-traitement des éléments de décoration.
En second lieu, le fait que le format produit soit une structure XML permet également de réaliser des contrôles de cohérence. Ces contrôles de cohérence peuvent être structurels (par exemple, un titre de niveau 4 ne peut pas être le fils d’un titre de niveau 2), mais ces contrôles peuvent également traiter des éléments liés à la nature du contenu (soit en volumétrie, soit en qualité de structure).
Nous voici donc avec un contenu structuré et validé produit simplement avec un outil courant de traitement de texte disponible sur la grande majorité des ordinateurs (Les suites MS-Office et LibreOffice doivent couvrir un périmètre proche des 100?% des producteurs de contenus).
Mais nous avons plus que cela.
La diffusion des contenus se fait majoritairement au travers de quelques formats :
- Natif, les fichiers issus de la sauvegarde à partir du traitement de texte au format DOCX ou ODF. C’est le plus simple.
- PDF, certains considèrent que cela représente soit une solution universelle et sécurité de diffuser des documents accessibles. La portabilité était un argument au début du XXIe siècle, mais plus aujourd’hui. Pour le reste, c’est une légende tenace.
- HTML (Hyper Texte Markup Language), très pratique pour une diffusion Web des contenus.
Et, il existe également d’autres besoins ou possibilités :
- XML DAISY (Digital Accessible Information System), très pratique pour une conversion en braille ou une lecture audio du contenu.
- EPUB (electronic publication), le format standardisé des livres numériques.
La multiplicité des cibles de publication peut représenter un travail conséquent et de fait représenter un frein à la bonne mise en pratique de la diffusion universelle (et donc accessible des contenus). Mais, pas si l’ensemble de ces cibles peut être adressés sans effort complémentaire et en garantissant à la fois la qualité du contenu et son adaptabilité au contexte de la cible.
Le contexte de la cible ?
Chaque format porte ses contraintes ou besoins. Dans le cadre du HTML, la forme graphique est spécifique au site Web (ou espace numérique) où le contenu doit être présenté. Pour le format EPUB, des métadonnées doivent être présentent et la présentation peut être spécifique. Le format XML DAISY ne réclame aucune mise en forme. Ce sont là quelques exemples de contextes de la cible.
Cela peut sembler représenter une difficulté de plus, pas un élément de facilité ! Aucunement.
Reprenons. Nous avons un contenu au format XML qui a été validé dans sa structure technique et sémantique. Nous devons proposer ce contenu dans différents formats qui sont tous (sauf un spécifique) basé sur une structure proche du XML (et même du XML pour certains). Et nous venons de format et de contenus édités facilement et disponible nativement au format XML. Une simple transformation élégante d’un schéma XML vers un autre schéma XML répond à la question. Simple et évident.
Le seul format spécifique (encore une fois) et le format PDF, mais dans ce cas, le plus simple est de directement utiliser les options d’enregistrement direct du contenu au format PDF à partir des outils de traitement de texte. Même si les puristes pourraient considérer que produire un fichier PDF à partir du XML source est finalement assez facile. C’est vrai, des outils permettent de le faire assez simplement et c’est d’ailleurs une excellente solution lorsque l’on souhaite diffuser au format PDF sous des formes différentes. Mais, dans la grande majorité des cas, le « sauver sous PDF » est le plus évident et pratique.
Pour les autres formats :
- HTML, est une structure très proche du XML, il suffira de prévoir d’ajouter quelques éléments de spécifications CSS (Cascading Style Sheet) de base afin de permettre l’application de n’importe quel charte graphique ou présentation sur les sites Web cibles.
- XML DAISY, XML vers XML. Pas de problème particulier.
- EPUB, basé sur HTML5, la production d’un EPUB devra respecter quelques éléments de structure, le fichier EPUB étant lui-même un ensemble de dossiers et contenus compressés au format ZIP. Les contenus étant au format HTML composé – le plus souvent – par un fichier HTML par chapitre de contenu.
Autre élément pratique dans cette démarche, les propriétés du document (titre, sujet, auteur et toutes les autres) sont disponibles dans quelques fichiers XML stockés dans l’arborescence du document. Donc, normalement pas d’édition supplémentaire des propriétés.
Pour les curieux
L’arborescence d’un document DOCX est la suivante :
- docProps qui contient les éléments de propriétés du contenu (core.xml en particulier)
- _rels
- word qui contient le contenu dans le fichier document.xml
- La racine contient le fichier : [Content_Types].xml
Références
Quelques références liées aux différents formats cités :
- Open doucement : http://opendocument.xml.org/specification
- Document Office : https://www.ecma-international.org/publications-and-standards/standards/ecma-376/
- XML :https://www.w3.org/XML/
- HTML : https://html.spec.whatwg.org/multipage/
- XML DAISY : https://daisy.org/activities/standards/daisy/daisy-3/z39-86-2005-r2012-specifications-for-the-digital-talking-book/ et https://cms-www-adm.bnf.fr/sites/default/files/2018-11/ref_num_daisy.pdf
- EPUB : https://www.w3.org/publishing/epub/epub-spec.html
- PDF : https://www.iso.org/fr/standard/51502.html
#accessibilité #bureautique #gestiondecontenu #XML #docx #odt #libreoffice #CMS #epub #daidy #PDF #format #accessibilite #cms #daisy #gestion-de-contenu #html #free-office #pdf #xml
Originally posted at: http://www.lhorens-marie.fr/de-lutilisation-des-formats-bureautiques-comme-pivots-de-production-de-contenus-accessibles-a-usages-multiples/
Kindles Now Support ePubs Sent by Email – It’s still converting them though to Amazon’s proprietary format

Amazon even has ePub listed as a supported format now for the Kindle Personal Documents Service, and there’s a note saying the Send-to-Kindle applications will also support ePub starting in late 2022. It gets treated as a typical personal document so there is no cover image, and the file is no longer in ePub format once it reaches a Kindle since Amazon converts it to Kindle format (AZW3).
The ability to send ePubs to Kindles has unofficially been supported for years, but you had to change the file extension to .png before sending. This just makes it easier and removes a step.
So regardless, I suppose it is at least easier now, with no cables or other intermediate steps. Note though that if you use free Calibre software still to convert your ePub book into Amazon’s format, it does show the book cover on the Kindle.
See https://blog.the-ebook-reader.com/2022/04/29/kindle-ereaders-now-support-epubs-sent-by-email/
#technology #epub #kindle #reading #ebooks
#Blog, ##books, ##epub, ##kindle, ##reading, ##technology
One person like that
Diaspora* Data Migration and Archival Lessons Learned
(So far)
This is a summary of my discoveries and learning over the past two months or so concerning Diaspora* data archives and references as well as JSON and tools for manipulating it, specifically jq.
It is a condensation of conversation mostly at my earlier Data Migration Tips & Questions (2022-1-10) thread, though also scattered elsewhere. I strongly recommend you review that thread and address general questions there.
Discussion here should focus on the specific information provided, any additions or corrections, and questions on how to access/use specific tools. E.g., how to get #jq running on Microsoft Windows, which I don't have specific experience with.
Archival Philosophy
I'm neither a maximalist nor minimalist when it comes to content archival. What I believe is that people should be offered the tools and choices they need to achieve their desired goal. Where preservation is preferred and causes minimal harm, it's often desirable. Not everything needs to be preserved, but too it isn't necessary to burn down every library one encounters as one journeys through life.
In particular, I'm seeking to preserve access for myself and others to previous conversations and discussions, and to content that's been shared and linked elsewhere. Several of my own posts have been submissions to Hacker News and other sites, for example, and archival at, say, the Internet Archive or Archive Today will preserve at least some access.
This viewpoint seems not to be shared by key members of the Diaspora* dev team and some pod administrators. As such, I'll note that their own actions and views reduce choice and agency amongst members of the Diaspora* community. The attitude is particularly incongruous given Diaspora*'s innate reliance on federation and content propagation according to the original specified intent of the content's authors and creators. This is hardly the first time Diaspora* devs have put their own concerns far above those of members of the Diaspora* community.
Information here is provided for those who seek to preserve content from their own profiles on Diaspora* servers likely to go offline, in the interest of maximising options and achieving desired goals. If this isn't your concern or goal, you may safely ignore what follows.
Prerequisites
The discussion here largely addresses working with a downloaded copy of Diaspora* profile data in JSON format.
It presumes you have jq installed on your system, and have a Bash or equivalent command-line / scripting environment. Most modern computers can offer jq though you will have to install it: natively on Linux, any of the BSDs, MacOS (via Homebrew), Windows (via Cygwin or WSL), and Android (via Termux). iOS is the only mass-market exception, and even there you might get lucky using iSH.
Create your archive by visiting your Pod's /user/edit page and requesting EXPORT DATA at the bottom of that page.
If you have issues doing so, please contact your Pod admin or other support contact(s). Known problems for some Joindiaspora members in creating archives are being worked on.
## Diaspora* post URLs can be reconstructed from the post GUID
The Diaspora* data extract does not include a canonical URL, but you can create one easily:
Post URL = /posts/
So for the GUID 64cc4c1076e5013a7342005056264835
We can tack on:
- protocol:
https:// - host_name:
pluspora.comSubstitute your intended Pod's hostname here. - the string literal
/posts/
to arrive at:
https://pluspora.com/posts/64cc4c1076e5013a7342005056264835
... which is the URL for a post by @Rhysy (rhysy@pluspora.com) in which I'd initially witten the comment this post is based on, at that post's Pluspora Pod origin.
Given that Pluspora is slated to go offline a few weeks from now, Future Readers may wish to refer to an archived copy here:
https://archive.ph/Y8mar
Once you have the URL, you can start doing interesting things with it.
Links based on other Pod URLs can be created
Using our previous example, links for the post on, e.g., diasp.org, diaspora.glasswings.com, diasp.eu, etc., can be generated by substituting for host_name:
- https://diasp.org/posts/64cc4c1076e5013a7342005056264835
- https://diasp.eu/posts/64cc4c1076e5013a7342005056264835
- https://diaspora.glasswings.com/posts/64cc4c1076e5013a7342005056264835
Simply having a URL on a pod does not ensure that the content will be propagated. A member of that pod must subscribe to the post first. In many cases this occurs through followers, though occasionally it does not.
You can trigger federation by specifically mentioning a user at that instance and having them request the page.
I'm not sure of when specifically federation occurs --- when the notification is generated, when the notification is viewed, or when the post itself is viewed. I've experienced such unfederated posts (404s) often as I've updated, federated, and archived my own earlier content from Joindiaspora to Glasswings. If federation occurs at some time after initial publication and comments the post URL and content should resolve, but comments made prior to that federation will not propagate.
(Pinging a profile you control on another pod is of course an excellent way to federate posts to that pod.)
Once a post is federated to a set of hosts it will be reachable at those hosts. If it has not yet been federated, you'll receive a "404" page, usually stating "These are not the kittens you're looking for. Move along." on Diaspora* instances.
(I'm not aware of other ways to trigger federation, if anyone knows of methods, please advise in comments.)
Note that comments shown on a post will vary by Pod, when and how it was Federated, and any blocks or networking issues between other Pods from which comments have been made. Not all instances necessarily show the same content, inconsistencies do occur.
Links to archival tools can be created by prepending their URLs to the appropriate link
- Archive.Today: https://archive.is/https://pluspora.com/posts/64cc4c1076e5013a7342005056264835
- Internet Archive: https://web.archive.org/*/https://pluspora.com/posts/64cc4c1076e5013a7342005056264835
Those will either show existing archives if they exist or provide links to submit the post if they do not.
Note that the Internet Archive does not include comments, though Archive.Today does, see: https://archive.is/almMw vs. https://web.archive.org/web/20220224213824/https://pluspora.com/posts/64cc4c1076e5013a7342005056264835
To include later comments, additional archival requests will have to be submitted.
My Archive-Index script does all of the above
See My current jq project: create a Diaspora post-abstracter.
https://diaspora.glasswings.com/posts/ed03bc1063a0013a2ccc448a5b29e257
That still has a few rough edges, but works to create an archive index which can be edited down to size. There's a fair bit of "scaffolding" in the direct output.
Note that the OLD and NEW hosts in the script specify Joindiaspora and Glasswings specifically. You'll want to adapt these to YOUR OWN old and newPod hostnames.
The script produces output which (after editing out superflous elements) looks like this in raw form:
## 2012
### May
**Hey everyone, I'm #NewHere. I'm interested in #debian and #linux, among other things. Thanks for the invite, Atanas Entchev!**
> Yet another G+ refuge. ...
<https://diaspora.glasswings.com/posts/cc046b1e71fb043d>
[Original](https://joindiaspora.com/posts/cc046b1e71fb043d) :: [Wayback Machine](https://web.archive.org/*/https://joindiaspora.com/posts/cc046b1e71fb043d) :: [Archive.Today](https://archive.is/https://joindiaspora.com/posts/cc046b1e71fb043d)
(2012-05-17 20:33)
----
**Does anyone have the #opscodechef wiki book as an ePub? Only available formats are online/web, or PDF (which sucks). I'm becoming a rapid fan of the #epub format having found a good reader for Android and others for Debian/Ubuntu.**
> Related: strategies for syncing libraries across Android and desktop/laptop devices. ...
<https://diaspora.glasswings.com/posts/e76c078ba0544ad9>
[Original](https://joindiaspora.com/posts/e76c078ba0544ad9) :: [Wayback Machine](https://web.archive.org/*/https://joindiaspora.com/posts/e76c078ba0544ad9) :: [Archive.Today](https://archive.is/https://joindiaspora.com/posts/e76c078ba0544ad9)
(2012-05-17 21:29)
----
Which renders as:
2012
May
Hey everyone, I'm #NewHere. I'm interested in #debian and #linux, among other things. Thanks for the invite, Atanas Entchev!
Yet another G+ refuge. ...
https://diaspora.glasswings.com/posts/cc046b1e71fb043d
Original :: Wayback Machine :: Archive.Today(2012-05-17 20:33)
Does anyone have the #opscodechef wiki book as an ePub? Only available formats are online/web, or PDF (which sucks). I'm becoming a rapid fan of the #epub format having found a good reader for Android and others for Debian/Ubuntu.
Related: strategies for syncing libraries across Android and desktop/laptop devices. ...
https://diaspora.glasswings.com/posts/e76c078ba0544ad9
Original :: Wayback Machine :: Archive.Today(2012-05-17 21:29)
I've been posting those in fragmenents by year as private posts to myself to facilitate both federation and archival of the content. In chunks as Diaspora* has a 2^16^ / 65,536 byte per-post size limit. It's a slow slog but I've only one more year (2021) to manually process at this point, with post counts numbering up to 535 per year.
The Internet Archive Wayback Machine (at Archive.org) accepts scripted archival requests
If you submit a URL in the form of https://web.archive.org/save/<URL>, the Wayback Machine will attempt to archive that URL.
This can be scripted for an unattended backup request if you can generate the set of URLs you want to save.
Using our previous example, the URL would be:
https://web.archive.org/save/https://pluspora.com/posts/64cc4c1076e5013a7342005056264835
Clicking that link will generate an archive request.
(IA limit how frequently such a request will be processed.)
Joindiaspora podmins discourage this practice. Among the more reasonable concerns raised is system load.
I suggest that if you do automate archival requests, as I have done, you set a rate-limit or sleep timer on your script. A request every few seconds should be viable. As a Bash "one-liner" reading from the file DIASPORA_EXTRACT.json.gz (change to match your own archive file), which logs progress to the timestamped file run-log with a YYYYMMDD-hms format, e.g., run-log.20220224-222158:
time zcat DIASPORA_EXTRACT.json.gz |
jq -r '.user .posts[] | "https://joindiaspora.com/posts/\(.entity_data .guid )"' |
xargs -P4 -n1 -t -r ~/bin/archive-url |
tee run-log.$(date +%Y%m%d-%H%M%S)
archive-url is a Bash shell script:
#!/bin/bash
url=${1}
echo -e "Archiving ${url} ... "
lynx -dump -nolist -width=1024 "https://web.archive.org/save/${url}" |
sed -ne '/[Ss]aving page now/,/^$/{/./s/^[ ]*//p;}' |
grep 'Saving page now'
sleep 4
Note that this waits 4 seconds between requests (sleep 4), which limits itself to a maximum of 900 requests per hour. There is NO error detection and you should confirm that posts you think you archived actually are archived. (We can discuss methods for this in comments, I'm still working on how to achieve this.)
The script could be improved to only process public posts, something I need to look into. Submitting private posts won't result in their archival, but it's additional time and load.
There is no automated submission mechanism for Archive.Today of which I'm aware.
Appending .json to the end of a Diaspora* URL provides the raw JSON data for that post:
https://joindiaspora.com/posts/64cc4c1076e5013a7342005056264835.json
That can be further manipulated with tools, e.g., to extract original post or comment Markdown text, or other information. Using jq is useful for this as described in other posts under the #jq hashtag generally.
Notably:
- Finding most frequent specific engagement peers
- Finding your most-engaged peers
- Extract the last (or other specified) comment(s) on a post
- Create a Diaspora archive-index
- "unjsonify-diaspora --- extract the original Markdown of a Diaspora* post. Note that this can be simplified to
jq -Mr '.text', excluding thesedcomponent (see comments on post).
As always: This is my best understanding
There are likely errors and omissions. Much of the behaviour and structure described is inferred. Corrections and additions are welcomed.
#DiasporaMigration #Migration #Diaspora #Help #Tips #JoindiasporaCom #jq #json #DataArchves #Archives
9 Likes
19 Comments
Renommer les EPUB à partir de leurs métadonnées
Après avoir récupéré près de 20 Go de fichiers EPUB, il a fallu les renommer en faisant apparaître le nom de l'auteur et le titre de l’œuvre, à l'aide de Calibre et de PowerShell.

1 Shares
 Marianne H W Robilliard (fl.1908-1920) , ‘Draped Female..’, “The International Studio”, 1909
Marianne H W Robilliard (fl.1908-1920) , ‘Draped Female..’, “The International Studio”, 1909
Source
International Studio an Illustrated Magazine of Fine and Applied Art. Volume vol. 37
Publication date 1909
Publisher New York. John Lane Co
10 Likes
Alright, here's the original leftcom mucho texto on its own: Herman Gorter's "Open Letter to Comrade Lenin." Like Historical Materialism from earlier, this one is also in Heavy Pancakes.
* EPUB
* MOBI
* PDF
* Libcom.org PDF
* HTML
* LibCom.Org's HTML
* Other eBooks
* This text is also available (albeit without the Wildcat Introduction) in the Left Communist reader Heavy Pancakes
#Communism #Marxism #Socialism #CouncilCommunism #ebooks #EPUB #Leninism #Bolshevism
Hey there, guess what! That's right, I made another EPUB! A collection of non-Leninist Marxist texts sampling from: Herman Gorter, Paul Mattick, Sylvia Pankhurst, Anton Pannekoek, & Otto Rühle.
— ☭Leek👑Marquis🥬(Lamda, 4'20", 69 IQ) (@iwschlom) May 14, 2021
It features some classics such as oops I ran out of charactershttps://t.co/AgNGaTWWwl pic.twitter.com/qvC94sGa2s
3 Likes
"For many online readers you simply can’t beat the convenience and clarity of reading e-books in #EPUB form" https://addons.mozilla.org/blog/read-epub-e-books-right-in-your-browser/ #mozilla #firefox

" #EPUb files are almost always accessible. Of course there are comic books and such that are images, but EPUB files are great! One can even read them in #Emacs with Nov.el (Nov-mode)." https://lists.orbitalfox.eu/archives/gemini/2021/006952.html
Folks at #Readium and #EDRLabs are trying to convince publishers that online #ebooks are safe, by trying to achieve some sort of #DRM -like “protection”. Needless to say, they’re bound to fail. https://github.com/readium/web/blob/master/docs/protection/introduction.md #EPUB #publishing
#WONTFIX: as far as #Calibre is concerned, visually-impaired users can simply just go f*ck themselves. Good to know. https://bugs.launchpad.net/calibre/+bug/1173190 https://bugs.launchpad.net/calibre/+bug/1187223 https://bugs.launchpad.net/calibre/+bug/1883775 #EPUB #FLOSS #a11y

Digital Books Available Here!
Epubs! Mobi Kindles! PDFs!
AVOID BUYING FROM AMAZON!
BUY DIRECT FROM THE AUTHOR!
The epubs and mobis are easily loaded into cp, smart phones, etc. The pdfs can be read on your pdf player, on your cp, smart phones, tablets, laptops, and desktop computers! Also printable! Just prints on A4 or A5, and you gets to have a book in your hands! All only for $9.99 per title! Except for Save Up! which is $3.99! Awesome!
How to Quit Smoking with Your Own Will Power! $9.99
3 files: 1 ePub, 1 mobi kindle, 1 pdf.
How to Quit Smoking with Your Own Will Power! SIMPLIFIED! $9.99
3 files: 1 ePub, 1 mobi kindle, 1 pdf.
DVD Shelf Plans $9.99
3 files: 1 ePub, 1 mobi kindle, 1 pdf.
BLURAY Shelf Plans $9.99
3 files: 1 ePub, 1 mobi kindle, 1 pdf.
Save Up! $3.99
3 files: 1 ePub, 1 mobi kindle, 1 pdf.
Ancient Cleansing Formulas $9.99
3 files: 1 ePub, 1 mobi kindle, 1 pdf
While the Author did not write this book, he only provide this for the benefits of Epub, Mobi, and PDF files, that he made available for all your health needs. He believes in this book so much he made the epubs, mobi, and pdf, so you can benefit from this quickly, without the tedious process of copying the OCR files by hand. This is an amazing book. Well worth the time to get it faster, and thus begin your detoxing quickly.
The PayPal Button is right on the page, just click the link below!
CLICK HERE FOR DIGITAL BOOKS AVAILABLE HERE!
#digital #books #epub #mobi #kindle #pdf #quitsmoking #stopsmoking #smokingcesation #smoking #quitsmoke #simplified #dvd #bluray #shelf #plans #diy #shelfplans #dvdshelfplans #diydvdshelfplans #blurayshelfplans #diyblurayshelfplans #saveup #savingup #savings #money #savingmoney #savingupmoney #ancientcleansingformulas #ancient #cleansing #formulas #detoxing #health #healing #flushing #liverflush #liver #eyewash #brighteyes

La version 0.10 de #Thunderbook, l’extension Mozilla #Thunderbird permettant d’exporter des messages (articles de flux inclus) en livre numérique (e-book), a été publiée.
L’extension est (enfin) compatible avec Thunderbird 68.
La nouvelle version est disponible à partir de sa page thunderbird.net ainsi qu’à partir de la page d’accueil du projet.

Ines Geister - vor 2 Tagen
#lesen #epub #tolino #thalia #kindle #bertelsmann #ebook #thriller #sciencefiction #esoterik #wiedergeburt #lebennachdemtod #reinkarnation #amazon #ebookde #hugendubel #weltbild #buecher.de #ibookstore #verkaufen
Hallo, ich möchte gerne mein #ebook #Lavodere vorstellen und gerne natürlich auch #verkaufen, weiß aber nicht, ob das hier richtig ist.
Ich habe noch nicht viel hier gemacht bzw. ist es schon (oh Schreck) 1 Jahr her. Es war so viel los in der Zeit und jetzt möchte ich gerne mal endlich Nägel mit Köpfen machen. Die Leute, die mich schon angeschrieben hatten, bitte ich um Verzeihung. Jetzt will ich mich wirklich auch beteiligen. Versprochen. (Allerdings bin ich mit mit der Handhabung immer noch nicht so sicher (wie auch, wenn ich nix mache hier) und bitte nötigenfalls um eure Unterstützung, die ich ja auch schon bekommen hatte. … damals.)
So, hier jetzt mein ebook, und ich hoffe, es gefällt und es werden einige auch kaufen. Ist ja mit 3,99 € auch nicht so super teuer. Es ist als #Lesebuch zur #Unterhaltung gedacht, auch, wenn das #Thema etwas #ungewöhnlich ist. Aber es ging mir auch um den #Gedanken, #wobleibeneigentlichdieganzenseelen, #wennjemandstirbt, egal ob #Tier oder #Mensch. Es ist vielleicht auch als #Krimi oder #Spannungsroman anzusehen. Auf jeden Fall #treibt und #trieb mich als #Veganerin beim #Schreiben natürlich das #Heil auch der #vielen, vielen #getöteten #Tiere an, und was aus ihnen wird, nachdem sie #gestorben sind. Kann man eigentlich #tote #Tiere #noch #essen ( #drüben )? Einfach nur ein #Gedankenexperiment.
Ich danke euch schon mal jetzt.
Herzliche Grüße
ghosti
http://www.bookrix.de/_ebook-ines-rosemarie-geister-lavodere/