#xml
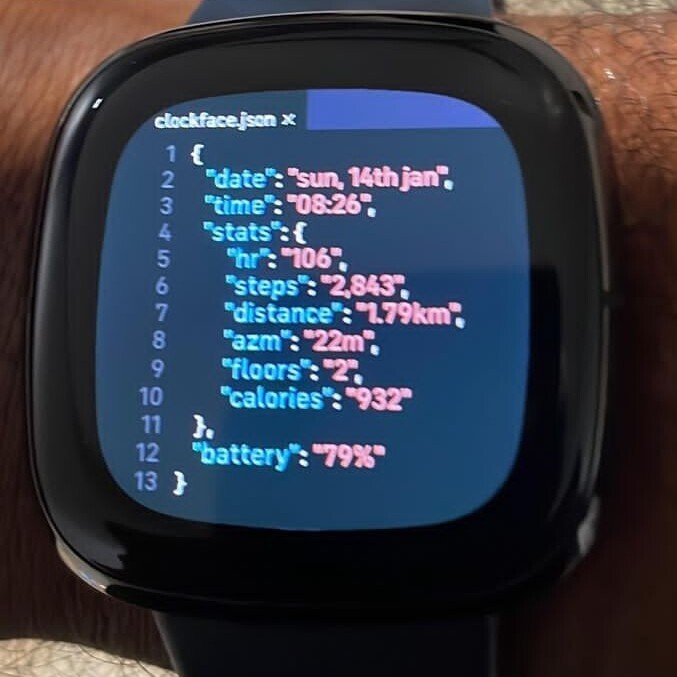
#syntax_highlighting #xml #gtksourceview #povray
[fr] Depuis le passage à la version 2.0 des fichiers de définition d'un langage, la coloration syntaxique ne se fait plus avec les fichiers en version 1.0. Il faut tout réécrire -- voire ajouter un fichier pour le type mime. La conversion d'une V1 vers la V2 ne se fait pas en 2 coups de cuillère à pot, justement et ce n'est pas une mince affaire... Donc, je n'ai plus de coloration syntaxique pour POV-Ray, ce qui est fort dommage, car ça m'aidait bien à m'y retrouver.
Language Definition v2.0 Reference
Language Definition v2.0 Tutorial -- C language
J'essaie de mettre mon nez là-dedans depuis quelques jours, mais je me perds dans les définitions... D'autant que je ne maitrise pas déjà les expressions de type regex -- ce qui est nécessaire, pourtant. C'est vraiment pas simple...
Project Zero: Gregor Samsa: Exploiting Java's XML Signature Verification
Earlier this year, I discovered a surprising attack surface hidden deep inside Java’s standard library: A custom JIT compiler processing untrusted XSLT programs, exposed to remote attackers during XML signature verification. This post discusses CVE-2022-34169, an integer truncation bug in this JIT compiler resulting in arbitrary code execution in many Java-based web applications and identity providers that support the SAML single-sign-on standard.
OpenJDK fixed the discussed issue in July 2022. The Apache BCEL project used by Xalan-J, the origin of the vulnerable code, released a patch in September 2022.
That is a really crazy exploit. So many levels of indirection.
#java #xml
https://googleprojectzero.blogspot.com/2022/11/gregor-samsa-exploiting-java-xml.html
#ThisWeekInSecurity: #OpenSSL #Fizzle, #Java #XML, and Nothing As It Seems
♲ This Week in Security – Hackaday - 2022-11-04 14:00:52 GMT
This Week in Security: OpenSSL Fizzle, Java XML, and Nothing As It Seems
The security world held our collective breaths early this week for the big OpenSSL vulnerability announcement. Turns out it’s two separate issues, both related to punycode handling, and they&…
Ce document a été initié avec MS-WORD puis compléter avec LibreOffice afin de démontrer l’interopérabilité des systèmes.
L’objectif de ce document est d’être à la fois l’explication du sujet et un élément de réalisation des tests. La première partie est consacrée aux explications du concept, la seconde au support de tests.
Quelques explications
Les principaux outils de rédactions de textes bureautiques tels que MS-Word ou LibreOffice utilisent un format basé sur un schéma XML (Open Document pour le monde libre et LibreOffice – fichiers ODF – et Open Office XML pour la solution propriétaire de Microsoft – fichiers DOCX). Quel que soit le format choisi, la passerelle entre les deux est simple et élégante. Nous sommes loin des sauvegardes sous forme binaire.
L’accès au contenu est évident puisque ces différents formats sont des compressions au format ZIP de l’arborescence des dossiers et des fichiers, du contenu et des propriétés du contenu. C’est l’ensemble contenu + propriétés + habillage graphique qui est nommé document.
Le premier intérêt de ces formats et de ces fichiers est leur facilité de lecture. Nous sommes dans le cadre fichiers accessibles et lisibles directement et simplement sans interprétation.
Le second intérêt vient du choix d’une structure XML. Ce choix signifie que nous travaillons avec des contenus qui sont par définition structurés et ainsi faciles à traiter ou à analyser. Mais, cela cache une autre caractéristique fondamentale : la séparation stricte du fond et de la forme. Nous ne sommes pas en présence d’un amas de décorations typographiques ou positionnement spatiaux de textes (comme dans le cas du format descriptif PDF – Portable Document Format) mais bien dans un contenu structuré.
La structure de ces contenus n’est pas le fruit du hasard ou de l’application technique d’un schéma XML, c’est simplement l’expression des styles utilisés au travers des interfaces utilisateurs. L’ensemble de la chaîne, du rédacteur au stockage technique, est donc directe et élégante.
Ne reste plus qu’à définir un modèle de document (donc un modèle de structure documentaire) qui fasse sens pour les rédacteurs et les lecteurs. Ce modèle documentaire va ainsi apporter une structure sémantique au contenu en complément de la structure technique directement issue du format XML.
Mais en quoi tout ceci permet-il de proposer (voire garantir) un contenu in fine accessible et utilisable sur l’ensemble des canaux pour la bonne distribution du contenu ?
En premier lieu, l’utilisation de styles prédéfinis dans un modèle de document (et en verrouillant les styles) contraint de manière évidente le rédacteur à ne plus utiliser son outil de traitement de texte comme une simple machine à écrire (avec du simple texte décoré afin de reproduire une pseudo structure du contenu) mais, comme un outil de contenu sémantique. En effet, si l’utilisateur refuse d’utiliser les styles mis à sa disposition, le résultat à la diffusion du contenu ne serait d’une longue chaîne de caractères sans aucune structure ni indication sémantique. La séparation du fond et de la forme entraîne de fait un non-traitement des éléments de décoration.
En second lieu, le fait que le format produit soit une structure XML permet également de réaliser des contrôles de cohérence. Ces contrôles de cohérence peuvent être structurels (par exemple, un titre de niveau 4 ne peut pas être le fils d’un titre de niveau 2), mais ces contrôles peuvent également traiter des éléments liés à la nature du contenu (soit en volumétrie, soit en qualité de structure).
Nous voici donc avec un contenu structuré et validé produit simplement avec un outil courant de traitement de texte disponible sur la grande majorité des ordinateurs (Les suites MS-Office et LibreOffice doivent couvrir un périmètre proche des 100?% des producteurs de contenus).
Mais nous avons plus que cela.
La diffusion des contenus se fait majoritairement au travers de quelques formats :
- Natif, les fichiers issus de la sauvegarde à partir du traitement de texte au format DOCX ou ODF. C’est le plus simple.
- PDF, certains considèrent que cela représente soit une solution universelle et sécurité de diffuser des documents accessibles. La portabilité était un argument au début du XXIe siècle, mais plus aujourd’hui. Pour le reste, c’est une légende tenace.
- HTML (Hyper Texte Markup Language), très pratique pour une diffusion Web des contenus.
Et, il existe également d’autres besoins ou possibilités :
- XML DAISY (Digital Accessible Information System), très pratique pour une conversion en braille ou une lecture audio du contenu.
- EPUB (electronic publication), le format standardisé des livres numériques.
La multiplicité des cibles de publication peut représenter un travail conséquent et de fait représenter un frein à la bonne mise en pratique de la diffusion universelle (et donc accessible des contenus). Mais, pas si l’ensemble de ces cibles peut être adressés sans effort complémentaire et en garantissant à la fois la qualité du contenu et son adaptabilité au contexte de la cible.
Le contexte de la cible ?
Chaque format porte ses contraintes ou besoins. Dans le cadre du HTML, la forme graphique est spécifique au site Web (ou espace numérique) où le contenu doit être présenté. Pour le format EPUB, des métadonnées doivent être présentent et la présentation peut être spécifique. Le format XML DAISY ne réclame aucune mise en forme. Ce sont là quelques exemples de contextes de la cible.
Cela peut sembler représenter une difficulté de plus, pas un élément de facilité ! Aucunement.
Reprenons. Nous avons un contenu au format XML qui a été validé dans sa structure technique et sémantique. Nous devons proposer ce contenu dans différents formats qui sont tous (sauf un spécifique) basé sur une structure proche du XML (et même du XML pour certains). Et nous venons de format et de contenus édités facilement et disponible nativement au format XML. Une simple transformation élégante d’un schéma XML vers un autre schéma XML répond à la question. Simple et évident.
Le seul format spécifique (encore une fois) et le format PDF, mais dans ce cas, le plus simple est de directement utiliser les options d’enregistrement direct du contenu au format PDF à partir des outils de traitement de texte. Même si les puristes pourraient considérer que produire un fichier PDF à partir du XML source est finalement assez facile. C’est vrai, des outils permettent de le faire assez simplement et c’est d’ailleurs une excellente solution lorsque l’on souhaite diffuser au format PDF sous des formes différentes. Mais, dans la grande majorité des cas, le « sauver sous PDF » est le plus évident et pratique.
Pour les autres formats :
- HTML, est une structure très proche du XML, il suffira de prévoir d’ajouter quelques éléments de spécifications CSS (Cascading Style Sheet) de base afin de permettre l’application de n’importe quel charte graphique ou présentation sur les sites Web cibles.
- XML DAISY, XML vers XML. Pas de problème particulier.
- EPUB, basé sur HTML5, la production d’un EPUB devra respecter quelques éléments de structure, le fichier EPUB étant lui-même un ensemble de dossiers et contenus compressés au format ZIP. Les contenus étant au format HTML composé – le plus souvent – par un fichier HTML par chapitre de contenu.
Autre élément pratique dans cette démarche, les propriétés du document (titre, sujet, auteur et toutes les autres) sont disponibles dans quelques fichiers XML stockés dans l’arborescence du document. Donc, normalement pas d’édition supplémentaire des propriétés.
Pour les curieux
L’arborescence d’un document DOCX est la suivante :
- docProps qui contient les éléments de propriétés du contenu (core.xml en particulier)
- _rels
- word qui contient le contenu dans le fichier document.xml
- La racine contient le fichier : [Content_Types].xml
Références
Quelques références liées aux différents formats cités :
- Open doucement : http://opendocument.xml.org/specification
- Document Office : https://www.ecma-international.org/publications-and-standards/standards/ecma-376/
- XML :https://www.w3.org/XML/
- HTML : https://html.spec.whatwg.org/multipage/
- XML DAISY : https://daisy.org/activities/standards/daisy/daisy-3/z39-86-2005-r2012-specifications-for-the-digital-talking-book/ et https://cms-www-adm.bnf.fr/sites/default/files/2018-11/ref_num_daisy.pdf
- EPUB : https://www.w3.org/publishing/epub/epub-spec.html
- PDF : https://www.iso.org/fr/standard/51502.html
#accessibilité #bureautique #gestiondecontenu #XML #docx #odt #libreoffice #CMS #epub #daidy #PDF #format #accessibilite #cms #daisy #gestion-de-contenu #html #free-office #pdf #xml
Originally posted at: http://www.lhorens-marie.fr/de-lutilisation-des-formats-bureautiques-comme-pivots-de-production-de-contenus-accessibles-a-usages-multiples/
Je mehr man sich mit #Lehrplänen und "schulinternen #Arbeitsplänen" beschäftigt, um so skurriler wird es...
Mal als Beispiel:
Lehrpläne
Das Ministerium für Schule und Bildung erstellt Inseltexte (a.k.a. "Lehrpläne") in Word und meißelt die Inhalte über Acrobat Pro in eine versiegelte PDF-Datei.
Immerhin ist die PDF-Datei durchsuchbar.
Aber zur Analyse, Verknüpfung und Weiterverarbeitung der Daten ist die PDF nicht geeignet.
Arbeitspläne
Das Ministerium veröffentlicht zusätzlich "Schulinterne Arbeitspläne" als Word-Dateien, in denen die Schulen ihre Unterrichtsvorhaben vorstellen, mit denen sie die Kompetenzerwartungen in den Lehrplänen stützen wollen.
Die Arbeitspläne sind Tabellen- und Textgräber, und als Inseltexte ebenfalls in sich abgeschlossen.
Daraus lassen sich nicht ohne zusätzliche Mühen z.B. Checklisten oder Verknüpfungen zu anderen Inhalten (Arbeitspläne anderer Fächer, Online-Dienste wie Edmond oder Logineo, Wikis etc.) erstellen.
Medienkompetenz
Der NRW-Kompetenzrahmen (den ich im Prinzip für sehr gut halte) fordert das hier:
- BEDIENEN UND ANWENDEN 1.2 Digitale Werkzeuge Verschiedene digitale Werkzeuge und deren Funktionsumfang kennen, auswählen sowie diese kreativ, reflektiert und zielgerichtet einsetzen.
Generell produziert das Ministerium Unmengen an Informationen zur "digitalen Medienkompetenz"; der Großteil im Word- oder InDesign-Format (und eben daraus generierte PDFs).
Es bräuchte offensichtlich die Metakompetenz, mal über die Anforderungen und Voraussetzungen des MKR zu reflektieren...
Fazit
Vom Ministerium bis zum Klassenraum verballern Menschen kostbare Lebenszeit damit, isolierte Inseltexte zu schreiben und zu pflegen und daraus irgendwelche Arbeitsvorlagen zu generieren, die auch wieder nur Inseltexte sind.
Deutschland, 2022.
Aber Hauptsache Weltmarktführer in KI, Blockchain und Flugtaxis sein wollen.
Lösungsansatz
Es gibt seit Ende der 1980er Jahre die Text Encoding Initaitive (TEI), die sich mit der Strukturierung und Organisation von Inhalten beschäftigt.
Seit 2005 geschieht das mit #XML.
Und jetzt überlege man sich das folgende Szenario:
- Das Ministerium strukturiert die Inhalte für Lehrpläne in (TEI P5) XML und veröffentlicht die unter Open Access Bedingungen.
- Die Lehrpläne sind modular aufgebaut, so dass man z.B. Allgemeinplätze nicht in zig Dokumenten nachpflegen muss, sondern nur an einer zentralen Stelle.
- Das Ministerium stellt auch Arbeitsplanmuster zur Verfügung, die den Schulen die Umsetzung erleichtern können.
- Die Schulen selber haben aber auch die Möglichkeit, die Lehrpläne zu kommentieren, Erfahrungen auszutauschen (weil jeder durch das Tagging genau weiß, was der andere meint) und Verknüpfungen zu andern Fächern oder Inhalten herzustellen.
- Die Form von Arbeitsplänen kann z.B. durch definierte XSLT-Transformationen vorgegeben werden, so dass ein Mindestmaß an Struktur und Vergleichbarkeit vorgegeben ist.
Die Bildungslandschaft wäre etwas weniger "verwaltet", denn auf einmal sind Lehrpläne kein Herrschaftswissen der Verwaltung/Ministerien mehr.
Ich habe aber so ein bisschen den Verdacht, dass man gerade das nicht möchte...
“We removed the RSS feed since this technology became obsolete”
Noooo... but I guess such are the sad times. Still I disagree with the statement. Many people in the linked discussion do too.
I for one still use RSS where I can, as it saves me from having to click here and there and bother with dynamically generated web pages. What do you feel when you read headlines like this?
Suchen ab sofort eine:n Entwickler:in mit Schwerpunkt PHP und Datenbanken in Vollzeit
Die #taz war die erste online lesbare #Tageszeitung Deutschlands. Sie bietet nach wie vor alltäglich die Möglichkeit, Dinge anders zu machen und ist immer noch #Konzern - #unabhängig.
Willst Du mit uns die zunehmend digitale #Zukunft des #Journalismus gestalten? Wir bieten ein kooperatives #Umfeld, das Raum für #Weiterentwicklung und #Kreativität lässt, aber auch strategisches #Denken erfordert und die Bereitschaft, alltägliche Probleme auch eigenverantwortlich zu lösen.
Wir suchen zeitnah ein:e Kolleg:in mit praktischer #Berufserfahrung in der #Softwareentwicklung. Es geht hierbei nicht um Webentwicklung, sondern um die #Aufbereitung und #Bereitstellung unserer #Verlagsprodukte für unsere #Apps, als #ePaper in verschiedenen Formaten und für unsere #Syndikationen.
Existierende #Softwareprojekte sollen übernommen werden - dies beinhaltet #Pflege, #Fortentwicklung und die #Dokumentation. Es sollte #Bereitschaft bestehen, sich in verschiedenartigen #Fremdcode einzuarbeiten. Wir wünschen uns #Offenheit für #Altes und #Neues gleichermaßen. Ferner solltest Du es gewohnt sein, mit #GIT und #Debian - Paketen zu arbeiten.
Von unserer Seite gefragt sind außerdem:
- Erfahrung mit #PHP. Ein Bewusstsein über die Notwendigkeit von #Typensicherheit ist notwendig
- Wissen, worauf es bei relationalen #Datenbanken (insb. #mariaDB) ankommt
- Verständnis für das Arbeiten mit #Volltext-Retrieval. Erfahrungen mit #Sphinx wären hilfreich
- Erfahrungen mit #GraphQl und #REST sowie die Kommunikation via #AMQP
- Das Umgehen mit #DOM und #XML, auch ausserhalb von #Web
- Grundlegende Kenntnisse der für Web-Applikationen nötigen Standards (XSLT, CSS, JS, JSON, HTTP)
- Verständnis für die Besonderheiten des #Webviews innerhalb der Apps
- Das Arbeiten in einer #Linux - Serverumgebung, dazu gehören auch #Bash - #Scripte und #Systemkonfigurationen
- Arbeiten mit #Redmine als Wiki für die #Dokumentation und als #Ticket-System
- Die Generierung von Debian-Paketen, vorzugsweise mit #Jenkins und #mini-buildd, sollte zum Alltag gehören
Wenn Du Lust darauf hast, in einem nach wie vor #politisch motivierten Umfeld als Teil des #EDV - Entwickler:innen-Teams auch #abteilungsübergreifend mit vielfältig interessanten Menschen, mit #Produktentwicklung, EDV, #Redaktion und #Verlag zusammenzuarbeiten, melde Dich. Bei der taz bieten wir nicht nur ein kollegiales Arbeitsumfeld, sondern auch familienfreundliche #Arbeitszeiten (flexible 36,5h/Woche, remote-Arbeit aktuell bis auf Weiteres aufgrund von Corona erwünscht, auch danach ist #Home-Office möglich, 30 Tage Urlaub) - es gibt ein ordentliches (und subventioniertes) Mittagessen im taz-Kantine.
Wir wollen diverser werden. Deshalb freuen wir uns besonders über Bewerbungen von People of Color und Menschen mit Behinderung. Deine Perspektiven sind uns wichtig und sollen in der taz vertreten sein. Die Arbeitsplätze und Toiletten sind weitestgehend barrierefrei. Das taz-Café ist mit dem Rollstuhl erreichbar.
Schicke uns deine Bewerbung und zeige uns, welche Kenntnisse und Erfahrungen Du gerne bei der taz entfalten würdest.
Es handelt sich um eine volle unbefristete Stelle ab taz-Lohngruppe 6. Arbeitsaufnahme zum nächstmöglichen Zeitpunkt. Schreibe uns gerne, ab wann Du einsteigen könntest und richte Deine Bewerbung an appjob@taz.de
Entwickler:in mit Schwerpunkt #XML / #XSLT für #taz.de in #Vollzeit ab sofort gesucht
Die #taz war die erste online lesbare #Tageszeitung Deutschlands. Sie bietet nach wie vor alltäglich die Möglichkeit Dinge anders zu machen und ist immer noch konzernunabhängig. Willst Du mit uns die zunehmend digitale Zukunft des #Journalismus gestalten? Wir bieten ein kooperatives Umfeld, das Raum für #Weiterentwicklung und #Kreativität lässt, aber auch strategisches #Denken erfordert und die Bereitschaft, alltägliche Probleme auch eigenverantwortlich zu lösen.
Wir suchen für unsere #Webinfrastruktur zeitnah eine:n Kolleg:in mit praktischer Berufserfahrung in der Entwicklung im Bereich #DATENMANAGEMENT, -TRANSFORMATION UND -ANALYSE, gerne auch als Quereinsteiger:in. Wichtig ist uns, dass Du nicht nur teamfähig bist, sondern bevorzugt gemeinsam arbeitest, auch flexibel und mit technischen Laien.
Im Bereich DATENMANAGEMENT, -TRANSFORMATION UND -ANALYSE integrieren wir Backendsysteme in unser Frontend taz.de. Wir kennen die Anwendungsschnittstellen unserer #Backends und transformieren diese in ein einheitliches XML-Format. Dabei stehen wir in enger Kommunikation mit Unix-Systemadministration und #Frontendentwicklung sowie internen Anwender:innen, externen Auftraggeber:innen und IT-Spezialist:innen. Immer wieder fordern uns neue Backendsysteme und Techniken heraus und immer wieder gilt es, Umbauten oder Fehler in bestehender #Infrastruktur zu finden und zu optimieren. Wir sind für **Import und Export **von #Daten rund um taz.de verantwortlich.
Anforderungen:
* Sicherer Umgang mit XML, #XPath und XSLT (Version 1.0).
* Du kannst #Bash-Skripte lesen und schreiben.
* Du scheust Dich nicht, auch auf produktiven Debian-Maschinen, mit Hilfe der Kommandozeile zu operieren, Zeichenketten bis zu ihrer Hexadezimaldarstellung zu untersuchen sowie Logdateien von Servern zu analysieren und Stacktraces versuchen zu verstehen.
* Du hast Erfahrungen mit #SQL - sowie #NoSQL -/Dokumentenorientierten - #Datenbanken.
* Du hast Erfahrungen mit vernetzten Serversystemen und Schnittstellen, insb. mit #REST, #RPC, #AMQP und #HTTP.
* Du hast Verständnis für System- und #Datenbankarchitektur und behältst dabei den Blick für das große Ganze und insb. Themen wie #Performance, #Datensparsamkeit und #Datenschutz sowie Sicherheit und Wartbarkeit sind Dir ein Anliegen.
* Du hast Erfahrungen mit #Content-Management-Systeme n und diese im besten Fall auch schon #headless im Einsatz genutzt.
Prima wären Erfahrungen mit #Git, #SVN, #Apache HTTP Server-Konfiguration, Regulären Ausdrücken sowie #JSON. Auch Erfahrungen mit einer weiteren #Programmiersprache, insb. einer deklarativen/funktionalen sind von Vorteil.
* Analytisches Denken und die Fähigkeit komplexe Zusammenhänge zu überblicken.
* Sehr gute Selbstorganisation und Planungsfähigkeit, insb. kannst Du Dich selbstständig in Techniken mit Hilfe von technischen (und meistens englischsprachigen) #Dokumentationen einarbeiten.
* Eigenverantwortliches Arbeiten und Durchhaltevermögen, auch wenn es stressig wird.
* Erfahrungen im Nachrichten- und Verlagsumfeld sind von Vorteil.
Wenn Du Lust darauf hast, in einem nach wie vor politisch motivierten Umfeld, als Teil des Web-Entwickler:innen-Teams auch abteilungsübergreifend mit vielfältig interessanten Menschen, mit #Produktentwicklung, #EDV, #Redaktion und Verlag sowie externen Dienstleistern zusammenzuarbeiten, melde Dich.
Bei der taz bieten wir nicht nur ein kollegiales Arbeitsumfeld, sondern auch familienfreundliche Arbeitszeiten (flexible 36,5h Vollzeit Woche und 30 Tage/Jahr Urlaub) und es gibt ein ordentliches, subventioniertes #Mittagessen im #taz-Café sowie die Möglichkeit, ein Job Rad zu nutzen.
Wir wollen diverser werden. Deshalb freuen wir uns besonders über Bewerbungen von People of Color und Menschen mit Behinderung. Deine Perspektiven sind uns wichtig und sollen in der taz vertreten sein. Die Arbeitsplätze und Toiletten sind weitestgehend barrierefrei. Das taz-Café ist mit dem #Rollstuhl erreichbar.
Schicke uns Deine #Bewerbung und zeige uns, welche Kenntnisse und Erfahrungen Du gerne bei der taz entfalten möchtest. Es handelt sich um eine volle unbefristete Stelle ab taz-Lohngruppe V. Arbeitsaufnahme ist zum nächstmöglichen Zeitpunkt. Schreibe uns gerne, ab wann Du einsteigen könntest und richte Deine Bewerbung an webjob@taz.de.
#Datenmanagement #Datenanalyse #Datentransformation #Stellenangebot #Stellenangebote #Job #Jobs #Arbeit #Brot
Get to know XML, a strict yet flexible markup language used for everything from documentation to graphics, and the basis of most government open standard formats
XML is a hierarchical markup language. It uses opening and closing tags to define data. It's used to store and exchange data, and because of its extreme flexibility, it's used for everything from documentation to graphics (or for interchanging data between different systems or applications).
Reading the sample XML, you might find there's an intuitive quality to the format. You can probably understand the data in this document whether you're familiar with the subject matter or not. XML is also extremely flexible. Unlike HTML, there's no predefined list of tags. You are free to create whatever data structure you need to represent.
See What is XML?
#technology #openstandards #XML #interoperability

XML is a hierarchical markup language. It uses opening and closing tags to define data. It's used to store and exchange data, and because of its extreme flexibility, it's used for everything from documentation to graphics. Here's a sample XML document:
Schon wieder eine #Stellenausschreibung
Webentwickler:in mit Schwerpunkt Frontend in Voll- oder Teilzeit für taz.de ab sofort gesucht
Die #taz war die erste online lesbare #Tageszeitung Deutschlands. Sie bietet nach wie vor alltäglich die Möglichkeit Dinge anders zu machen und ist immer noch #Konzern-unabhängig.
Willst Du mit uns die zunehmend digitale #Zukunft des #Journalismus gestalten? Wir bieten ein kooperatives #Umfeld, das Raum für #Weiterentwicklung und #Kreativität lässt, aber auch strategisches #Denken erfordert und die Bereitschaft, alltägliche Probleme auch eigenverantwortlich zu lösen.
Wir suchen zeitnah ein:e Kolleg:in mit praktischer Berufserfahrung in der Webentwicklung, gerne auch als Quereinsteiger:in. Wichtig ist uns, dass Du nicht nur teamfähig bist, sondern bevorzugt gemeinsam arbeitest, auch mit technischen Laien.
Im #Frontend-Bereich von taz.de stehen viele Veränderungen an. Derzeit gestalten und bauen wir unseren Verlagsbereich neu. Als nächstes plant die #taz, den redaktionellen Bereich zu relaunchen. Dabei werden wir vieles überdenken und verändern. Neben der Pflege und der Weiterentwicklung von taz.de erwartet dich ein bunter Strauß an Themen: #Datenschutz, #Tracking, #Ads, #SEO, strukturierte #Daten, #Feeds, #Barrierefreiheit und vieles mehr.
Anforderungen:
- Grundlegende Kenntnisse der für Web-Applikationen nötigen Standards ( #HTML5 , #DOM , #XML , #XSLT , #CSS3 , #JS , #JSON , #HTTP , #REST)
- Sicherer Umgang mit #ES6 , #jQuery und #CSS-Präprozessoren und -frameworks sind wünschenswert
- Du kannst auch ohne #Frameworks responsive #Seiten erstellen, die #crossbrowser funktionieren - eine gewisse Lust auf Urschleim ist nicht verkehrt
- Wir setzen auf Serversite #Rendering und #XML als Datengrundlage, die sich aus verschiedenen #CMS speist. Bislang setzen wir auf #xslt. Das wollen wir durch serverside javascript ablösen.
- Prima wären Erfahrungen mit #nodejs
- Interesse an #UX und #UI
- Einarbeitung und Weiterentwicklung von #Fremdcode
- Sicherer Umgang mit #Versionierungssystemen
- Erfahrungen im Nachrichten- und Verlagsumfeld wären von Vorteil
- Sehr gute #Selbstorganisation
Wenn Du Lust darauf hast, in einem nach wie vor politisch motivierten Umfeld als Teil des Web-Entwickler:innen-Teams auch abteilungsübergreifend mit vielfältig interessanten Menschen, mit Produktentwicklung, EDV, Redaktion und Verlag zusammenzuarbeiten, melde Dich.
Bei der taz bieten wir nicht nur ein kollegiales Arbeitsumfeld, sondern auch familienfreundliche #Arbeitszeiten (flexible #Vollzeit 36,5h/Woche, remote-Arbeit aktuell bis auf Weiteres aufgrund von #Corona erwünscht, auch danach ist prinzipiell #Home-Office möglich, 30 Tage #Urlaub) – es gibt ein ordentliches (und subventioniertes) #Mittagessen im taz-Café.
Wir wollen diverser werden. Deshalb freuen wir uns besonders über Bewerbungen von People of Color und Menschen mit Behinderung. Deine Perspektiven sind uns wichtig und sollen in der taz vertreten sein. Die Arbeitsplätze und Toiletten sind weitestgehend #barrierefrei. Das taz-Café ist mit dem #Rollstuhl erreichbar.
Schicke uns deine #Bewerbung und zeige uns, welche Kenntnisse und Erfahrungen Du gerne bei der taz entfalten würdest.
Es handelt sich um eine volle unbefristete Stelle ab taz-Lohngruppe V. Auch Teilzeit wäre denkbar, wenn Vollzeit für dich nicht möglich ist. Arbeitsaufnahme zum nächst möglichen Zeitpunkt. Schreibe uns gerne, ab wann Du einsteigen könntest und richte Deine Bewerbung an webjob@taz.de.
Wir freuen uns auch über Weiterleitung, ihr findet die Stellenausschreibung auch unter https://taz.de/jobs
Problème avec gestionnaire de mot de passe Revelation après mise à jour de Ubuntu LTS 18.04 vers 20.04: j'ai fait cette mise à jour chez ma compagne, et sous 20.04, le gestionnaire de mot de passe Revelation n'existe plus !! Tous les mots de passe inaccessibles, et même pas un message d'alerte ! Il n'est plus dans les paquets, galère. J'ai réussi à installer une nouvelle version de Revelation sous forme d'un flatpack, j'ai donc de nouveau accès, ouf. Mais par contre, l'export des mdp, pour passer à Keepass XC, se fait sous forme d'un fichier xml compliqué, que Keepass ne peut pas importer ! Je ne trouve pas comment le convertir !!
Est-ce que l'un de vous a eu ce problème ? Une solution ? Franchement, quelle galère, c'est la première fois que j'ai ça avec Ubuntu, mais c'est gratiné !
#Ubuntu #password #xml #conversion #revelation #problème #LTS #upgrade