
#oracle


Another reminder to get yourself on OpenJDK ASAP before the hatchet man comes. I'm glad that is the default on Linux. Other platforms aren't so lucky. #oracle #java https://www.theregister.com/2024/06/20/oracle_java_licence_teams/
6 Likes
1 Shares
I watched Oracle do this same maneuver with their DB several times years ago. From then on I always used OpenJDK. This is their MO. It's why I recommend never using any Oracle product of any kind ever. #oracle #programming https://www.theregister.com/2024/06/10/fortune_200_oracle_java_audit/
1 Comments


13.12.2023 Förderung von Open Source in Kinderschuhen
Weiter Milliarden für die Internet-Giganten
Als man noch Opposition war, versicherten Grüne und SPD, dass sie Open-Source-Software in der Entwicklung aber vor allem im Einsatz in Schulen und Universitäten aber auch Behörden unterstützen würden. Nach 2 Jahren Ampel-Regierung sieht man, dass auch aus diesem Verprechen nichts geworden ist.
Netzpolitik.org schreibt zu dem Thema: Die Bundesregierung gibt Milliardensummen für Produkte großer IT-Konzerne wie Microsoft und Oracle aus und nimmt dabei die starke Herstellerabhängigkeit in Kauf. Das geht aus einer Antwort auf eine Kleine Anfrage der Linken-Politikerin Anke Domscheit-Berg zum Thema Digitale Souveränität und Open-Source-Lösungen hervor.
Die Abgeordnete veröffentlichte zu ihrer Frage und der Antwort der Regierung eine Analyse, von der die Bundesregierung Teile zur Verschlusssache erklärte. Das ist auch eine Möglichkeit die Opposition ruhig zu stellen ...
Einige Zahlen:
- Microsoft bekommt über Rahmenverträge 1,2 Milliarden Euro,
- Oracle allein 4,8 Milliarden Euro,
- für OSS - Open Source Software - wurden vom Digitalministerium von den mehr als 22 Millionen Euro lediglich 121.000 Euro ausgegeben,
- für IT Dienstleistungen wurden 18,6 Millionen Euro für OSS gezahlt,
- allerdings gingen 99,5 Prozent des Gesamtvolumenvon ca. 3,5 Milliarden Euro für Dienstleistungen für proprietäre Software drauf.
Die Bundesregierung bewertet die Abhängigkeiten von den Internetgiganten weiterhin "als kritisch", tut aber wenig dagegen. Und das, obwohl der Entwurf für das neue Onlinezugangsgesetz (OZG) von Behörden fordert „IT-Komponenten dort, wo es technisch möglich und wirtschaftlich ist, als OSS bereitzustellen“ und ihr vor anderer Software den Vorrang zu geben, „deren Quellcode nicht öffentlich zugänglich ist oder deren Lizenz die Verwendung, Weitergabe und Veränderung einschränkt“.
Wenn das Gesetz wäre, kann es "eigentlich" keinen Grund mehr geben bei den Big5 zu kaufen ...
Mehr dazu bei https://netzpolitik.org/2023/digitale-souveraenitaet-milliarden-fuer-oracle-microsoft-und-co-statt-fuer-open-source/
Kategorie[21]: Unsere Themen in der Presse Short-Link dieser Seite: a-fsa.de/d/3xQ
Link zu dieser Seite: https://www.aktion-freiheitstattangst.org/de/articles/8617-20231213-foerderung-von-open-source-in-kinderschuhen.html
Link im Tor-Netzwerk: http://a6pdp5vmmw4zm5tifrc3qo2pyz7mvnk4zzimpesnckvzinubzmioddad.onion/de/articles/8617-20231213-foerderung-von-open-source-in-kinderschuhen.html
Tags: #OpenSource #Software #Big5 #GAFAM #Microsoft #Oracle #Onlinezugangsgesetz.OZG #Bundesregierung #Lizenzen #DigitaleSouveränität #Transparenz #Informationsfreiheit #Verschlusssache #Datenschutz #Datensicherheit #Ungleichbehandlung
6 Likes
How To #Survive Being #Sold to #Oracle
Watch: https://www.youtube.com/watch?v=GcvhKaelazs (be careful this URI goes to YouTube and they track every click and sell your data)
For better #privacy watch here: https://media.ccc.de/v/camp2023-57278-how_to_survive_being_sold_to_oracle
#economy #software #OpenOffice #LibreOffice #history #internet #community #freedom #capitalism
2 Likes
1 Shares
SUSE, Oracle und CIQ gründen Enterprise Linux Association
https://linuxnews.de/suse-oracle-und-ciq-gruenden-enterprise-linux-association/
#suse #oracle #ICQ #RedHat

Oracle und SUSE verhindern das Sommerloch
https://linuxnews.de/suse-und-oracle-verhindern-das-sommerloch/
#oracle #suse #RedHat
#ThisWeekinSecurity: #Oracle #Opera, #Passkeys, and #AirTag #RFC

There’s a problem with Opera. No, not that kind of opera. The Oracle kind. Oracle OPERA is a Property Management Solution (PMS) that is in use in a bunch of big-name hotels around the world. The PMS is the system that handles reservations and check-ins, talks to the phone system to put room extensions in the proper state, and generally runs the back-end of the property. It’s old code, and handles a bunch of tasks. And researchers at Assetnote found a serious vulnerability. CVE-2023-21932 is an arbitrary file upload issue, and rates at least a 7.2 CVSS.
https://hackaday.com/2023/05/05/this-week-in-security-oracle-opera-passkeys-and-airtag-rfc/
2 Likes
1 Shares

It seems people are skittish enough now about Oracle that they are using OpenJDK instead at record rates, Oracle now only has 35% of the JVM install base. I made the "OpenJDK or bust" decision for any project I had sway over after watching a customer go through a licensing bait and switch with Oracle that cost them countless millions of dollars. After that I would never recommend their databases, Java, or cloud offerings. The problem though is that Oracle represents the overwhelming majority of the effort keeping OpenJDK and Java going. The more people run into the open source arms the more draconian I imagine Oracle will be. I'm mostly not using the JVM for projects right now but it is something to watch out for. #Java #openjdk #oracle https://sdtimes.com/software-development/eclipse-foundation-finds-significant-momentum-for-open-source-java-this-year/

3 Likes
1 Shares

6 Likes
2 Shares
A Day in a Life as a Business Intelligence Developer
with Gerhard Höll
Many paths lead to the goal if you want to become a Business
Intelligence Developer. There is no defined route, much more important
is the fun and enthusiasm for this job. Gerhard has always been
interested in the BI environment and enjoyed working in it the most. In
his studies in Business Informatics, he got to know the whole range of
BI, from Business Intelligence to Data Warehousing and Data Analytics.
In his role as Recruiting Support, he can give you important tips about
his job that can increase your chances of landing your dream job.
::: {.wp-block-spacer style="height: 15px;"}
:::
Are there any main tasks that arise on a daily basis?
That depends on the project. As a developer, not really, apart from the
coordination rounds within the development team. I am currently
involved in a project in which I have contact with the business side,
DWH operations and the developers of the source system. In this project,
the entire spectrum of data warehouse development is covered -- from
requirements gathering to development and operation. We look at making
sure the data warehouse is running smoothly and that up-to-date data is
being delivered daily for users to work with. When you come in after
your morning coffee, the first task that comes up is to see if the load
runs have gone correctly. It is important that the business users can
work with the BI and DWH system.
::: {.wp-block-spacer style="height: 15px;"}
:::
 {.wp-image-58454
{.wp-image-58454
width="1024" height="683"}
::: {.wp-block-spacer style="height: 0px;"}
:::
What influence do you have on the customer's work?
Efficiency and benefit should always be at the priority to make sure
that the customer gets the most value from what we do. You can avert or
recommend various things that can harm or benefit the system. In this
way you can influence customers in their decisions. In the area of
evaluations and graphical presentations, you also have influence on the
use of the various presentation options. The goal is always to recognize
facts and contexts more quickly through the evaluations in order to gain
new insights.
::: {.wp-block-spacer style="height: 0px;"}
:::
What do you enjoy the most?
The best part of my job is dealing with issues together with my
colleagues and finding solutions together. You are involved in exchanges
and coordination on a wide variety of topics. Both at the customer's
site and with colleagues at virtual7. It is always a welcome change to
work together with other people and not just to develop in a quiet room.
Of course, that also has to be done, but the variety and interaction is
crucial for me here.
::: {.wp-block-spacer style="height: 0px;"}
:::
Which skills are essential for a job at virtual7?
The requirements are first of all of a technological nature, of course.
Since we work with Oracle products, you should be familiar with Oracle
technologies. These include: The Oracle Database, SQL and PL/SQL, Oracle
Data Integrator and Oracle Analytics Server. You will also need to be
familiar with the methods to create data warehouse architectures and
models, dashboards and analytics. Since we are always working with
different people and teams, soft skills are just as important, if not a
bit more important. Communication is especially important here. You have
to be able to ask the right questions. Likewise, being able to present
and explain complicated issues in a simple way. The knowledge level and
perspectives of individuals on different aspects can vary greatly, so
you need to have an understanding and background knowledge of the
project and the subject area. It is not always easy to get everyone
involved on the same page. Apart from that, you need to be a team player
and be able to organize yourself in your team. As a developer you always
need a good grasp and analytical thinking, as well as convincing
presentation skills.
::: {.wp-block-spacer style="height: 0px;"}
:::
 {.wp-image-58453
{.wp-image-58453
width="1024" height="683"}
::: {.wp-block-spacer style="height: 0px;"}
:::
Is Oracle a must have to work for us?
Our clients make it a point to see in resumes that you have experience
with Oracle. So hard facts: X/Y years of Oracle experience. Everything
that is Oracle-specific about the tools can be learned quickly.
Methodological knowledge in the data warehouse and BI environment are
much more important in our projects. You should know modeling approaches
and how to represent certain facts and justify them. It is important to
be honest about your experience, this will bring you and us much further
than a pimped CV.
::: {.wp-block-spacer style="height: 0px;"}
:::
Good to know that...
- virtual7 likes to celebrate successes together.
- the job is not just a consulting assignment, but a safe place to work for several years.
- you mainly work at the customer's and can also do a lot at virtual7.
- team building is huge internally, be it at the conference, chat 'n' chills or meet-ups.
- you can be yourself and (almost) everything is informal.
Der Beitrag <strong>A Day in a Life as a Business Intelligence
Developer</strong>
erschien zuerst auf virtual7 GmbH - Blog.
https://blog.virtual7.de/a-day-in-a-life-as-a-business-intelligence-developer/
#virtual7 #digitalisierung #deutschland #virtual #digitalezukunft #digital #zukunft #agile #virtual7gmbh #BI #job #Oracle #Recruiting #SQL
1 Shares
Gedanken zum Datenbanktuning
Es kommt immer wieder es vor, dass (Oracle-) Datenbankanwendungen „zu
langsam" sind. Dann wird versucht herauszufinden woran es liegt und wenn
man Glück hat findet sich eine Idee das verursachende SQL-Statement so
zu ändern, dass die Anwendung „schnell genug" wird. Es wird bei diesem
ganzen Vorgang oft übersehen, dass die Ursachen(n) für die schlechte
Performance nicht erst im SQL-Statement begründet ist, sondern viel
früher ihren Ursprung hat.
Die Planung einer performanten Datenbankanwendung beginnt mit der
Planung der Datenbank. Um eine Datenbank planen zu können sollten die
Anforderungen an die mit ihr zu realisierenden Anwendungen bekannt sein.
Einige der Fragen, die für die Planung relevant sind:
\
Ist es eine ERP-Anwendung oder ein Datawarehouse?\
Gibt es Tabellen mit sehr unterschiedlichen Satzlängen?\
Wird mit der Anwendung hauptsächlich abgefragt oder Daten bearbeitet?\
Gibt es mehrere Anwendungen, die mit den Daten arbeiten sollen und haben
diese Anwendungen unterschiedliche Anwendungsmuster?
Mit den gesammelten Anforderungen kann die Physik der Datenbank geplant
werden.
::: {.wp-block-spacer style="height: 36px;"}
:::
Tablespaces und Blockgrößen {#h-tablespaces-und-blockgr-en}
Die Blockgröße(n) der Tablespaces sollten an die Anforderungen der
Anwendung angepasst werden. Zur Erinnerung: Oracle liest immer nur ganze
Blöcke und nicht einzelne Datensätze. Falls es in den Anforderungen an
die einzelnen Tabellen große Unterschiede gibt sollten die Tabellen auf
Tablespaces mit geeigneten unterschiedlichen Blockgrößen verteilt
werden.
Kleine Blockgrößen (2KB/4KB) eignen sich für kurze Satzlängen auf die
oft einzeln zugegriffen wird. Sie eignen sich nicht für lange Satzlängen
und wenn oft auf große Mengen an Datensätzen zugegriffen wird.
Große Blockgrößen (8KB -- 32KB) eignen sich für lange Satzlängen und
wenn große Datenmengen sequenziell abgefragt werden.
Falls wegen eines kleinen Datensatzes ein großer Block gelesen werden
muss oder falls wegen eines langen Datensätzes dieser auf mehrere Blöcke
verteilt werden muss (chaining), so mindert dies die Performance der
späteren Anwendung.
Gegebenenfalls lohnt es sich Tablespaces mit unterschiedlichen
Blockgrößen anzulegen.
::: {.wp-block-spacer style="height: 36px;"}
:::
Tabellen {#h-tabellen}
Die Datensätze einer Tabelle werden in den Blöcken des zu verwendenden
Tablespaces gespeichert. Sobald ein Block eines Tablespace einer Tabelle
zugewiesen ist gehört er zu dieser Tabelle, auch dann, wenn alle
Datensätze in diesem Block gelöscht wurden (high water mark). Bei einem
Full Table Scan werden auch diese inzwischen leeren Blöcke gelesen und
kosten Zeit. Oracle bietet mehrere Möglichkeiten diese Blöcke
freizugeben ( export/import, alter table .. shrink space, usw...)
Oracle vermerkt alle leeren oder teilweise leeren Blöcke einer Tabelle
in die noch Datensätze geschrieben werden dürfen in einer Freelist.\
Mit den Speicherparametern pctfree und pctused (Prozentwerte) kann
angegeben werden, unter welchen Bedingungen ein Block auf die Freelist
gesetzt oder von dieser entfernt wird. Ist der Block zu mehr als pctfree
frei, so wird der Block auf die Freelist gesetzt. Ist der Block zu mehr
als pctused belegt, so wird er von der Freelist genommen.
::: {.wp-block-spacer style="height: 36px;"}
:::
Chaining {#h-chaining}
Falls ein Datensatz nicht in einen Block passt, so wird er über mehrere
Blöcke verteilt. Dann müssen um diesen einen Datensatz zu lesen alle
diese Blöcke nacheinander gelesen werden. (Ob in einer Tabelle solche
Datensätze existieren kann z.B. in user_tables in der Spalte chain_cnt
überprüft werden)
Zu Chaining kommt es, wenn große Datensätze in (zu) kleine Blöcke
geschrieben werden, oder wenn bestehende Datensätze beim Aktualisieren
verlängert werden (z.B. wenn ein varchar2-Wert verlängert wird). Falls
der Datensatz länger ist als die Blockgröße, so lässt sich chaining
nicht verhindern. In diesem Fall kann man darüber nachdenken die Tabelle
in einen Tablespace mit größerer Blockgröße zu verschieben.
Falls die Verlängerung eines Datensatzes aufgrund der
Anwendungsanforderungen vorhersehbar ist, so kann durch setzen eines
geeigneten Werts für pctused der Tabelle dafür gesorgt werden, dass in
den Blöcken genügend freier Platz gelassen wird, so dass eine
Verlängerung eines Datensatzes in den bestehenden Block passt. Für
Tabellen mit Datensätzen, die nur einmal geschrieben und dann nicht mehr
verändert werden, kann pctused hoch gewählt werden.
Falls Datensätze regelmäßig gelöscht und neu geschrieben werden, so
sollte pctfree so gewählt werden, dass ein neuer Datensatz in den noch
freien Platz eines bereits teilweise belegten Blocks passt:
::: {.wp-block-spacer style="height: 36px;"}
:::
Beispiel {#h-beispiel}
Blockgröße: 4096 Bytes\
mittlere Satzlänge eines Datensatzes (user_tables.avg_row_len): 400
Bytes
Zwei Bemerkungen:
- Diese mittlere Länge kann sich ändern.
- Viele Datensätze sind sicherlich länger als 400 Bytes.
Mit „select sum(c.DATA_LENGTH) from user_tab_columns c where
c.TABLE_NAME = \$NAME\$\
können wir die maximale Länge eines Datensatzes ermitteln.
\
Beispiel a) die mittlere Datensatzlänge wäre 600 Bytes.\
Mit pctfree = 15 (4096*0,15 = 614) sind wir auf der sicheren Seite.
Beispiel b) die mittlere Datensatzlänge wäre 6000 Bytes.\
Da wir die Verteilung der Datensatzlängen nicht kennen, müssen wir eine
Annahme treffen:\
pctfree = 20 (2096*0,20 = 819) sollte für die meisten Datensätze
ausreichend sein.
Wir tauchen ein bisschen tiefer ein. Falls wir mit verlässlichern Werten
arbeiten wollen, können wir uns mit etwas Aufwand bessere Kennzahlen
ermitteln:
dump() liefert uns einen String, der u.a. die Länge in Bytes des
Ausdrucks zurückgibt:
Z.B: select dump( 'ä' ) from dual;
DUMP('Ä')
Typ=96 Len=2: 195,164
Dies nutzen wir, um die Länge der einzelnen Spalten zu ermitteln und
diese aufzusummieren.
2 Anmerkungen:
- Jede Spalte benötigt ein zusätzliches Byte Speicherplatz. (Dies berücksichtigen wir nachfolgend)
- NULL-Spalten (auch mehrere) am Ende eines Datensatzes benötigen keinen Speicherplatz. (Dies berücksichtigen wir nachfolgend nicht!)
mit
select '+ coalesce( to_number( regexp_substr( dump( ' || rpad( column_name, 32, ' ' ) ||q'{ ), 'Len=(\d*):', 1, 1, 'x', 1 ) ), 0) +1}' as term
from user_tab_columns
where table_name = $tabellenname$
order by column_id;
können wir uns den schreibintensiven Teil des folgenden Statements
erzeugen lassen:
with len_ as
( select coalesce( to_number( regexp_substr( dump( ), 'Len=(\d):', 1, 1, 'x', 1 ) ), 0) +1
+ coalesce( to_number( regexp_substr( dump( ), 'Len=(\d):', 1, 1, 'x', 1 ) ), 0) +1 + …
+ coalesce( to_number( regexp_substr( dump( ), 'Len=(\d*):', 1, 1, 'x', 1 ) ), 0) +1 as bytes from $tabellenname$ )
select min(bytes), avg(bytes), max(bytes), stddev(bytes) from len_;
Hinweis: für sehr große Tabellen kann diese Auswertung lang dauern. In
diesem Fall sollte sie auf eine ausreichend große repräsentative Menge
begrenzt werden ( where rownum < X ).
Die Werte sind wegen Anmerkung 2 nicht 100% zuverlässig. Für eine
Abschätzung der Verteilung der Datensatzlängen sind sie aber
ausreichend. Unter der Annahme, dass die Längen normalverteilt sind,
kann die Mindestgröße für pctfree wie folgt bestimmt werden:
pctfree = 100 * ( avg + stddev ) / Blockgröße (für ~84% aller
Datensätze ausreichend)\
pctfree = oder 100 * ( avg + 2*stddev ) / Blockgröße (für ~98% aller
Datensätze ausreichend)
Siehe auch:
Der Beitrag Gedanken zum
Datenbanktuning
erschien zuerst auf virtual7 GmbH - Blog.
https://blog.virtual7.de/gedanken-zum-datenbanktuning/
#virtual7 #digitalisierung #deutschland #virtual #digitalezukunft #digital #zukunft #agile #Finance #OracleDatabase #Technology #Chaining #database #Datenbank #Oracle #Tuning
One person like that
1 Shares
GNU Linux Debian 11 (bullseye) - how to install virtualbox 6.1

<span style="color: #00ffff;">lsb_release -a</span>; # tested with
Distributor ID: Debian
Description: Debian GNU/Linux 11 (bullseye)
Release: 11
Codename: bullseye
<span style="color: #00ffff;">su - root
wget https://download.virtualbox.org/virtualbox/6.1.32/virtualbox-6.1_6.1.32-149290~Debian~bullseye_amd64.deb
</span>sha512sum 7e977fde8a2fc370d7df24f761e75eced308ea17037113db877bd799abec4a3a9b6324fcbfda2d2a67d63fbe23b822abbd36ab0f9af4fc5c352df04a97dbe550
# needs to be dpkg installed manually
<span style="color: #00ffff;">apt update && apt upgrade
apt install software-properties-common libvpx6 libqt5opengl5 libqt5x11extras5 libsdl1.2debian
linux-headers-amd64 linux-headers-$(uname -r) gcc make
dpkg -i virtualbox-6.1_6.1.32-149290~Debian~bullseye_amd64.deb
/sbin/vboxconfig
</span>
#linux #gnu #gnulinux #opensource #administration #sysops #oracle #virtualbox #debian #gnu-linux
Originally posted at: https://dwaves.de/2022/02/24/gnu-linux-debian-11-bullseye-how-to-install-virtualbox-6-1/
2 Likes
Transparently Patching PWNKIT with Ksplice https://blogs.oracle.com/linux/post/transparently-patching-pwnkit-with-ksplice #oracle #linux #kernel #security
The Freezing of tasks in the #Linux #kernel and how it's used by #Ksplice https://blogs.oracle.com/linux/post/freezing-tasks-ksplice #oracle
One person like that
![]()
ZFS is probably THE most controversial filesytem in the known universe:
“FOSS means that effort is shared across organizations and lowers maintenance costs significantly” (src: comment by JohnFOSS on itsfoss.com)
“The whole purpose behind ZFS was to provide a next-gen filesystem for UNIX and UNIX-like operating systems.” (src: comment by JohnK3 on itsfoss.com)
“The performance is good, the reliability and protection of data is unparalleled, and the flexibility is great, allowing you to configure pools and their caches as you see fit. The fact that it is independent of RAID hardware is another bonus, because you can rescue pools on any system, if a server goes down. No looking around for a compatible RAID controller or storage device.”
“after what they did to all of SUN’s open source projects after acquiring them. Oracle is best considered an evil corporation, and anti-open source.”
“it is sad – however – that licensing issues often get in the way of the best solutions being used” (src: comment by mattlach on itsfoss.com)
“Zfs is greatly needed in Linux by anyone having to deal with very large amounts of data. This need is growing larger and larger every year that passes.” (src: comment by Tman7 on itsfoss.com)
“I need ZFS, because In the country were I live, we have 2-12 power-fails/week. I had many music files (ext4) corrupted during the last 10 years.” (src: comment by Bert Nijhof on itsfoss.com)
“some functionalities in ZFS does not have parallels in other filesystems. It’s not only about performance but also stability and recovery flexibility that drives most to choose ZFS.” (src: comment by Rubens on itsfoss.com)
“Some BtrFS features outperform ZFS, to the point where I would not consider wasting my time installing ZFS on anything. I love what BtrFS is doing for me, and I won’t downgrade to ext4 or any other fs. So at this point BtrFS is the only fs for me.” (src: comment by Russell W Behne on itsfoss.com)
“Btrfs Storage Technology: The copy-on-write (COW) file system, natively supported by the Linux kernel, implements features such as snapshots, built-in RAID, and self-healing via checksumming for data and metadata. It allows taking subvolume snapshots and supports offline storage migration while keeping snapshots. For users of enterprise storage systems, Btrfs provides file system integrity after unexpected power loss, helps prevent bitrot, and is designed for high-capacity and high-performance storage servers.” (src: storagereview.com)
BTRFS is GPL 3.0 licenced btw.
bachelor projects are written about btrfs vs zfs (2015)
so…
ext4 is good for notebooks & desktops & workstations (that do regular backups on a separate, external, then disconnected medium)
is zfs “better” on/for servers? (this user says: even on single disk systems, zfs is “better” as it prevents bit-rot-file-corruption)
with server-hardware one means:
- computers with massive computational resources (CPUs, RAM & disks)
- at least 2 disks for RAID1 (mirroring = safety)
- or better: 4 disks for RAID10 (striping + mirroring = speed + safety)
- zfs wants direct access to disks without any hardware raid controller or caches in between, so it is “fine” with simple SATA onboard connections or hba cards that do nothing but provide SATA / SAS / NVMe ports or hardware raid controllers that behave like hba cards (JBOD, some need firmware flashed, some need to be jumpered)
- fun fact: this is not the default for servers. servers (usually) come with LSI (or other vendor) hardware raid cards, that might be possible to JBOD jumper or flash) but that would mean: zfs is only good for servers WITHOUT hardware raid cards X-D (and those are (currently still) rare X-D)
- but they would be “perfect” fit for a consumer-hardware PC (having only SATA ports) used as server (many companies not only Google but also Proxmox and even Hetzner test out that way of operation, but it might not be the perfect fit for every admin, that rather spends some bucks extra and wants to provide companies with the most reliable hardware possible (redundant power supplies etc.)
- maybe that is also a cluster vs mainframe “thinking”
- so in a cluster, if some nodes fail, it does not matter, as other nodes take over and are replaced fast (but some server has to store the central database, that is not allowed to fail X-D)
- in a non-cluster environment, things might be very different
- fun fact: this is not the default for servers. servers (usually) come with LSI (or other vendor) hardware raid cards, that might be possible to JBOD jumper or flash) but that would mean: zfs is only good for servers WITHOUT hardware raid cards X-D (and those are (currently still) rare X-D)
- “to EEC or not to EEC the RAM”, that is the question?:
- zfs also runs on machines without EEC but:
- in semi-professional purposes non-EEC might be okay
- for companies with critical data maximum error correction EEC is a must (as magnetic fields / sunflares could potentially flip some bits in RAM, then write the faulty data back to disk, ZFS can not correct that)
- “authors of a 2010 study that examined the ability of file systems to detect and prevent data corruption, with particular focus on ZFS, observed that ZFS itself is effective in detecting and correcting data errors on storage devices, but that it assumes data in RAM is “safe”, and not prone to error”
- “One of the main architects of ZFS, Matt Ahrens, explains there is an option to enable checksumming of data in memory by using the ZFS_DEBUG_MODIFY flag (zfs_flags=0x10) which addresses these concerns.[73]” (wiki)
- zfs also runs on machines without EEC but:
zfs: snapshots!
zfs has awesome features such as:
- snapshots:
- allows to recover from “ooops just deleted everything” errors and ransomeware attacks (unless the ransomeware is zfs “aware” and deletes all snapshots)
- extundelete does not work well for ext4
- testdisk -> photorec can recover data from ext4 but not the /directory/structure/filenames!!!
- ext4 can do snapshots as well with lvm2, but those lvm2 snapshots are more temporary “buffers” that can run out of changes-written-space and are then disgarded, so not “real” and “permanent” snapshots that can be restored or copied to a different system without time-limitation.
- zfs comes with data compression to safe disk space (won’t work well for “binary” data such as jpg or mp4 but anything text)
many more featuers:
- Protection against data corruption. Integrity checking for both data and metadata.
- Continuous integrity verification and automatic “self-healing” repair
- Data redundancy with mirroring, RAID-Z1/2/3 [and DRAID]
- Support for high storage capacities — up to 256 trillion yobibytes (2^128 bytes)
- Space-saving with transparent compression using LZ4, GZIP or ZSTD
- Hardware-accelerated native encryption
- Efficient storage with snapshots and copy-on-write clones
- Efficient local or remote replication — send only changed blocks with ZFS send and receive
(src)
how much space do snapshots use?
look at WRITTEN, not at USED.

https://papers.freebsd.org/2019/bsdcan/ahrens-how_zfs_snapshots_really_work/
performance?
so on a single-drive system, performance wise ext4 is what the user wants.
on multi-drive systems, the opposite might be true, zfs outperforming ext4.
it is a filesystem + a volumen manager! 🙂
“is not necessary nor recommended to partition the drives before creating the zfs filesystem” (src, src of src)
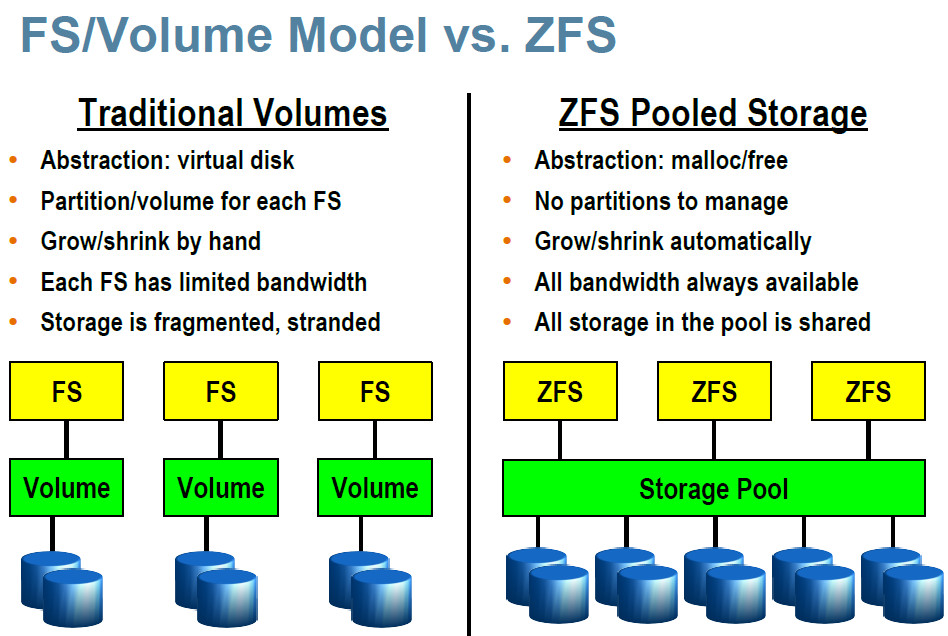
http://perftuner.blogspot.com/2017/02/zfs-zettabyte-file-system.html
RAID10?
there is no raid10 in zfs, only raid5, which means: at least one disk is used for checksums
- “raid5 or raidz distributes parity along with the data
- can lose 1x physical drive before a raid failure.
- Because parity needs to be calculated raid 5 is slower then raid0, but raid 5 is much safer.
- RAID 5 requires at least 3x hard disks in which one(1) full disk of space is used for parity.
- raid6 or raidz2 distributes parity along with the data
- can lose 2x physical drives instead of just one like raid 5.
- Because more parity needs to be calculated raid 6 is slower then raid5, but raid6 is safer.
- raidz2 requires at least 4x disks and will use two(2) disks of space for parity.
- raid7 or raidz3 distributes parity just like raid 5 and 6
- but raid7 can lose 3x physical drives.
- Since triple parity needs to be calculated raid 7 is slower then raid5 and raid 6, but raid 7 is the safest of the three.
- raidz3 requires at least 4x, but should be used with no less then 5x disks, of which 3x disks of space are used for parity.
- raid10 or raid1+0 is mirroring and striping of data.
- The simplest raid10 array has 4x disks and consists of two pairs of mirrors.
- Disk 1 and 2 are mirrors and separately disk 3 and 4 are another mirror.
- Data is then striped (think raid0) across both mirrors.
- One can lose one drive in each mirror and the data is still safe.
- One can not lose both drives which make up one mirror, for example drives 1 and 2 can not be lost at the same time.
- Raid 10 ‘s advantage is reading data is fast.
- The disadvantages are the writes are slow (multiple mirrors) and capacity is low.”
ZFS supports SSD/NVMe caching + RAM caching:
more RAM is better than an dedicated SSD/NVMe cache, BUT zfs can do both! which is remarkable.
(the optimum probably being RAM + SSD/NVMe caching)
ubuntu makes zfs the default filesystem
ZFS & Ubuntu 20.04 LTS
“our ZFS support with ZSys is still experimental.”
https://ubuntu.com/blog/zfs-focus-on-ubuntu-20-04-lts-whats-new
ZFS licence problems/incompatibility with GPL 2.0 #wtf Oracle! again?
Linus: “And honestly, there is no way I can merge any of the ZFS efforts until I get an official letter from Oracle that is signed by their main legal counsel or preferably by Larry Ellison himself that says that yes, it’s ok to do so and treat the end result as GPL’d.” (itsfoss.com)
comment by vagrantprodigy: “Another sad example of Linus letting very limited exposure to something (and very out of date, and frankly, incorrect information about it’s licensing) impact the Linux world as a whole. There are no licensing issues, OPENZFS is maintained, and the performance and reliability is better than the alternatives.” (itsfoss.com)


it is Open Source, but not GPL licenced: for Linus, that’s a no go and quiet frankly, yes it is a problem.
“this article missed the fact that CDDL was DESIGNED to be incompatible with the GPL” (comment by S O on itsfoss.com)
it can also be called “bait”
“There is always a thing called “in roads”, where it can also be called “bait”.
“The article says a lot in this respect.
“That Microsoft founder Bill Gate comment a long time ago was that “nothing should be for free.”
That too rings out loud, especially in today’s American/European/World of “corporate business practices” where they want what they consider to be their share of things created by others.
Just to be able to take, with not doing any of the real work.
That the basis of the GNU Gnu Pub. License (GPL) 2.0 basically says here it is, free, and the Com. Dev. & Dist.
License (CDDL) 1.0 says use it for free, find our bugs, but we still have options on its use, later on downstream.
..
And nothing really is for free, when it is offered by some businesses, but initial free use is one way to find all the bugs, and then begin charging costs.
And it it has been incorporated into a linux distribution, then the linux distribution could later come to a legal halt, a legal gotcha in a court of law.
In this respect, the article is a good caution to bear in mind, that the differences in licensing can have consequences, later in time.Good article to encourage linux users to also bear in mind, that using any programs that are not GNU Gen. Pub. License (GPL) 2.0 can later on have consequences for use having affect on a lot of people, big time.
That businesses (corportions have long life spans) want to dominate markets with their products, and competition is not wanted.
So, how do you eliminate or hinder the competition?
… Keep Linux free as well as free from legal downstream entanglements.”
(comment by Bruce Lockert on itsfoss.com)
Imagine this: just as with Java, Oracle might decide to change the licence on any day Oracle seems fit to “cash in” on the ZFS users and demand purchasing a licence… #wtf Oracle
Guess one is not alone with that thinking: “Linus has nailed the coffin of ZFS! It adds no value to open source and freedom. It rather restricts it. It is a waste of effort. Another attack at open source. Very clever disguised under an obscure license to trap the ordinary user in a payed environment in the future.” (comment by Tuxedo on itsfoss.com)
GNU Linux Debian warns during installation:

“Licenses of OpenZFS and Linux are incompatible”
- OpenZFS is licensed under the Common Development and Distribution License (CDDL), and the Linux kernel is licensed under the GNU General Public License Version 2 (GPL-2).
- While both are free open source licenses they are restrictive licenses.
- The combination of them causes problems because it prevents using pieces of code exclusively available under one license with pieces of code exclusively available under the other in the same binary.
- You are going to build OpenZFS using DKMS in such a way that they are not going to be built into one monolithic binary.
- Please be aware that distributing both of the binaries in the same media (disk images, virtual appliances, etc) may lead to infringing.
“You cannot change the license when forking (only the copyright owners can), and with the same license the legal concerns remain the same. So forking is not a solution.” (comment by MestreLion on itsfoss.com)
OpenZFS 2.0
“This effort is fast-forwarding delivery of advances like dataset encryption, major performance improvements, and compatibility with Linux ZFS pools.” (src: truenas.com)
tricky.
of course users can say “haha”  “accidentally deleted millions of files” “no backups” “now snapshots would be great”
“accidentally deleted millions of files” “no backups” “now snapshots would be great”
or come up with a smart file system, tha can do snapshots.
how to on GNU Linux Debian 11:
https://openzfs.github.io/openzfs-docs/Getting%20Started/Debian/index.html
note:
with ext4 it was recommended to put GNU Linux /root and /swap on a dedicated SSD/NVMe (that then regularly backs up to the larger raid10)
but than the user would miss out on the zfs awesome restore snapshot features, which would mean:
- no more fear of updates
- take snapshot before update
- do system update (moving between major versions of Debian 9 -> 10 can be problematic, sometimes it works, sometimes it will not)
- test the system according to list of use cases (“this used to work, this too”)
- if update breaks stuff -> boot from a usb stick -> roll back snapshot (YET TO BE TESTED!)
Links:
https://openzfs.org/wiki/Main_Page
#linux #gnu #gnulinux #opensource #administration #sysops #zfs #openzfs #filesystem #filesystems #ubuntu #btrfs #ext4 #gnu-linux #oracle #licence
Originally posted at: https://dwaves.de/2022/01/20/the-most-controversial-filesytem-in-the-known-universe-zfs-so-ext4-is-faster-on-single-disk-systems-btrfs-with-snapshots-but-without-the-zfs-licensing-problems/
4 Likes
1 Comments