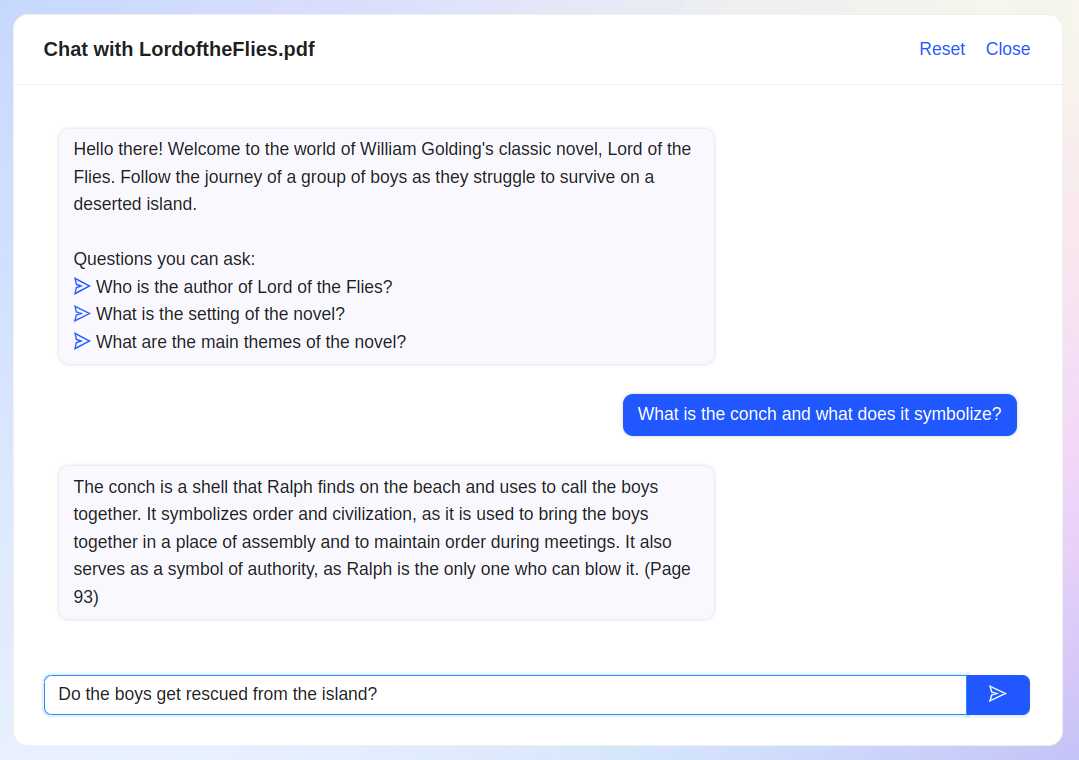
ChatPDF lets you chat with a PDF file.
To give it a whirl, I looked around on my machine and found a file called 2102.08176.pdf. I have been trying to get in the habit of immediately renaming downloaded files with something resembling their contents, but I still have lots of files lying around with cryptic names like "2102.08176.pdf". So, without opening the file and looking at the contents first, I uploaded it to ChatPDF. (You all are about to discover what kinds of files I have lying around on my machine.) Here's the conversation I had about it. All without looking at the file.
ChatPDF: Hello there! This PDF file discusses the development of flat maps that improve on the Winkel Tripel projection. The authors have developed six error measures to rate flat map projections on their verisimilitude to the sphere, and have found a new variant that performs slightly better than the Winkel Tripel.
Here are three example questions you may have about this PDF file:
What are the six error measures used to rate flat map projections?
How does the new Gott-Wagner variant compare to the Winkel Tripel in terms of error score?
What are some potential applications for these improved flat maps?
Me: What are the six error measures to rate flat map projections on their verisimilitude to the sphere?
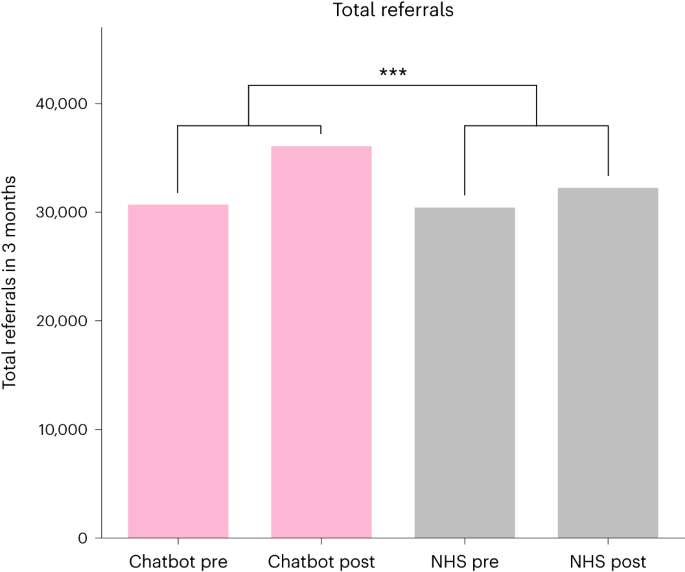
ChatPDF: The authors of this PDF file developed six error measures to rate flat map projections on their verisimilitude to the sphere. These measures are Isotropy, Area, Flexion, Skewness, Distances, and Boundary Cuts. The first two depend on the metric of the projection, while the next two depend on its first derivatives. This information can be found on page 1 of the PDF file.
Me: What is meant by "isotropy"?
ChatPDF: In the context of this PDF file, "isotropy" refers to one of the six error measures used to rate flat map projections on their verisimilitude to the sphere. Isotropy is a measure of how well a projection preserves the relative sizes of features on the globe. Specifically, it measures how much distortion there is in the areas of regions on the map compared to their corresponding areas on the globe. The isotropy score is calculated using a root mean square (RMS) value of ln(ai/bi), where ai and bi are the semi-major and semi-minor axes of a Tissot ellipse that represents an infinitesimal circle on the globe projected onto the map. This information can be found on page 1 of the PDF file.
Me: What is a Tissot ellipse?
ChatPDF: In the context of this PDF file, a Tissot ellipse is an ellipse that represents an infinitesimal circle on the globe projected onto a map. It is used to measure how much distortion there is in the areas of regions on the map compared to their corresponding areas on the globe. The Tissot ellipse has semi-major and semi-minor axes, a and b, which are used to calculate the isotropy score, one of six error measures used to rate flat map projections on their verisimilitude to the sphere. This information can be found on page 1 of the PDF file.
Me: What is meant by "Flexion"?
ChatPDF: In the context of this PDF file, "Flexion" is one of the six error measures used to rate flat map projections on their verisimilitude to the sphere. Flexion is a measure of how much a projection bends or curves a geodesic (the shortest path between two points on a sphere) when it is projected onto a flat map. Specifically, it measures the amount of bending per degree of travel on the geodesic. A flexion score of F=1 means that there is a bending of 1 degree per degree of travel on the geodesic. This information can be found on page 2 of the PDF file.
Me: What is meant by "Boundary Cuts"?
ChatPDF: In the context of this PDF file, "Boundary Cuts" is one of the six error measures used to rate flat map projections on their verisimilitude to the sphere. Boundary cuts refer to the lines that separate regions on a map that correspond to different regions on the globe. The boundary cut error, B, is a measure of how much distortion there is in these lines compared to their corresponding lines on the globe. Specifically, it measures the length of the boundary cut in degrees divided by 720°. A boundary cut of 180° has an error of B=0.25, while a boundary cut of 360° has an error twice as bad as a boundary cut of 180° because it is like making two boundary cuts of 180° in a row. Error values for some standard map projections can be found in Table I on page 2 of the PDF file.
Me: What is meant by "Skewness"?
ChatPDF: In the context of this PDF file, "Skewness" is one of the six error measures used to rate flat map projections on their verisimilitude to the sphere. Skewness is a measure of how much a projection accelerates in a forward or backward direction when traveling along a geodesic (the shortest path between two points on a sphere) that is projected onto a flat map. Specifically, it measures the amount of acceleration per degree of travel on the geodesic. A skewness score of S=1 means that there is an acceleration of 1 degree per degree of travel on the geodesic. On conformal maps like the complete stereographic, flexion and skewness errors are equal, in that case being F=S=1. This information can be found on page 2 of the PDF file.
Me: What is meant by "Area"?
ChatPDF: In the context of this PDF file, "Area" is one of the six error measures used to rate flat map projections on their verisimilitude to the sphere. Area refers to how much distortion there is in the sizes of regions on a map compared to their corresponding sizes on the globe. The area error, A, is a measure of how much larger or smaller a region appears on the map compared to its corresponding region on the globe. Specifically, it measures the ratio of the area on the map to the area on the globe. An area score of A=1 means that there is no distortion in area, while an area score greater than 1 means that regions are enlarged and an area score less than 1 means that regions are shrunk. Error values for some standard map projections can be found in Table I on page 2 of the PDF file.
Me: Of the six error measures, do the authors consider them all of equal value, or are there some that they consider more important than others?
ChatPDF: The authors of the PDF file do not consider all six error measures to be of equal value. In fact, they argue that some error measures are more important than others. Specifically, they argue that the errors in area, distance, and angle are more important than the errors in flexion, skewness, and boundary cuts. This is because errors in area, distance, and angle have a more direct impact on how accurately a map represents the globe. The authors also note that boundary cuts and skewness are required in the error budget to avoid terrible maps winning the overall errors contest. This information can be found on page 2 and page 8 of the PDF file.
Me: What is the overall errors contest?
ChatPDF: The overall errors contest referred to in the PDF file is a competition between different flat map projections to determine which one has the lowest overall error. The overall error is calculated as a weighted sum of the six individual error measures (area, distance, angle, flexion, skewness, and boundary cuts), with weights chosen to reflect the relative importance of each measure. The goal of this competition is to find the best possible flat map projection that accurately represents the globe. This information can be found on page 2 of the PDF file.
Me: What is the best flat map projection found, according to this paper?
ChatPDF: According to the PDF file, the best flat map projection found is a new class of flat double-sided maps (like phonograph records) which have correct topology and vastly improved error scores. The azimuthal equidistant version of this map has an error score of 0.881, making it the most accurate flat map of Earth yet. This information can be found on page 1 and page 21 of the PDF file.
Me: Does the best flat map projection found have a name?
ChatPDF: The PDF file does not mention a specific name for the new class of flat double-sided maps that are considered the most accurate flat maps of Earth yet. However, it does describe them as being like phonograph records and having correct topology. The azimuthal equidistant version of this map has an error score of 0.881, which is significantly better than any other flat map projection tested in the paper. This information can be found on page 1 and page 21 of the PDF file.
Me: Why does the the best flat map projection found have to be double-sided (like phonograph records)?
ChatPDF: The best flat map projection found in the PDF file is double-sided (like phonograph records) because it allows for a Northern Hemisphere map to be on one side of the map and a Southern Hemisphere map to be on the other side. This is useful because it allows for the North Circumpolar stars to be shown in the center of the Northern Hemisphere map, and the map can be rotated in your hand to follow the rotation of the sky. Additionally, double-sided maps have correct topology and vastly improved error scores compared to one-sided maps. This information can be found on page 1 and page 31 of the PDF file.
Me: How does the azimuthal equidistant version of the best flat map projection work?
ChatPDF: The azimuthal equidistant version of the best flat map projection found in the PDF file is a double-sided disk that uses an Azimuthal Equidistant projection. This projection preserves distances from the center point of the map, making it useful for navigation and measuring distances. The map has a uniform scale along meridians and is a compromise projection like the Winkel Tripel. Errors in isotropy and area are less noticeable, and local shapes are π/2:1 elongated at the edge. Antarctica does not look too small, and Australia does not look too squashed. In sums of squares of normalized errors in isotropy, area, flexion, skewness, distances, and boundary cuts, this is the best overall flat map yet produced with an error score of 0.881. This information can be found on page 18 and page 20 of the PDF file.
Me: What is the Gott-Wagner variant?
ChatPDF: The Gott-Wagner variant is a map projection that is described in the PDF file as being useful and having a slightly better error score than the Winkel Tripel projection. The Gott-Wagner variant is not described in detail, but it is mentioned on page 1 of the PDF file as being presented alongside the new class of flat double-sided maps that are considered to be the most accurate flat maps of Earth yet.
Me: What applications are there for the the best flat map projection found?
The best flat map projection found in the PDF file has several potential applications. The map can be used for navigation and measuring distances because it preserves distances from the center point of the map. It can also be used for educational purposes, as it provides an accurate representation of the Earth's surface with correct topology. Additionally, the double-sided nature of the map allows for a Northern Hemisphere map to be on one side and a Southern Hemisphere map to be on the other side, which is useful for showing North Circumpolar stars in the center of the Northern Hemisphere map and following the rotation of the sky. This information can be found on page 1 and page 31 of the PDF file.
Me: What is the importance of showing North Circumpolar stars in the center of the Northern Hemisphere map?
ChatPDF: Showing North Circumpolar stars in the center of the Northern Hemisphere map is important because it allows for the map to be rotated in your hand to follow the rotation of the sky. This is useful for stargazing and navigation purposes. Additionally, North Circumpolar stars are always visible in the night sky from a given location in the Northern Hemisphere, so they are a useful reference point for finding other stars and constellations. This information can be found on page 31 of the PDF file.
All in all, pretty impressive! The one question I have at this point is: was all this accurate? To determine that, I need to actually open the file and read it myself. I'm also curious what's in the file that I didn't think to ask about.
The experience reminds me very much of my late-night conversations with ChatGPT, except this time it's about a specific paper.
ChatPDF
#solidstatelife #llms #nlp #generativemodels #chatbots #chatgpt