2 Likes
#gpt

2 Likes
2 Likes
1 Shares
Verstehen Chatbots, was wir ihnen sagen und was wir meinen? Chatbots und generative künstliche Intelligenz im Zusammenhang.#LargeLanguageModels #KünstlicheIntelligenz #KI #AI #GPT #NeuronaleNetze #Transformer #Prompting #Trainingsdaten #ExplainableAI #XAI #ITTech #Kultur #PsychologieHirnforschung
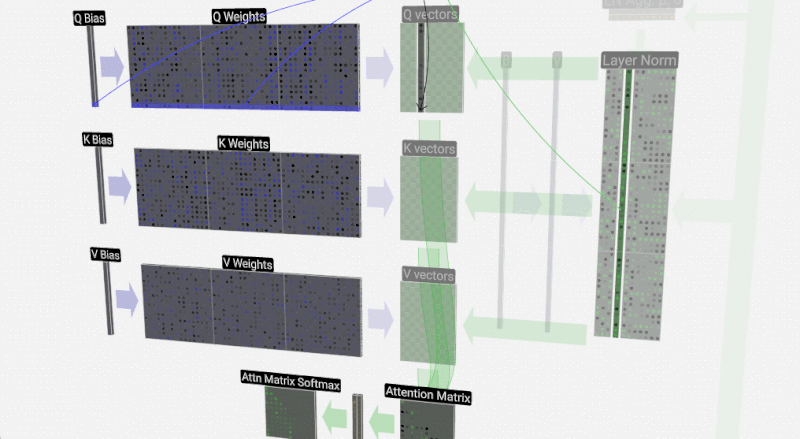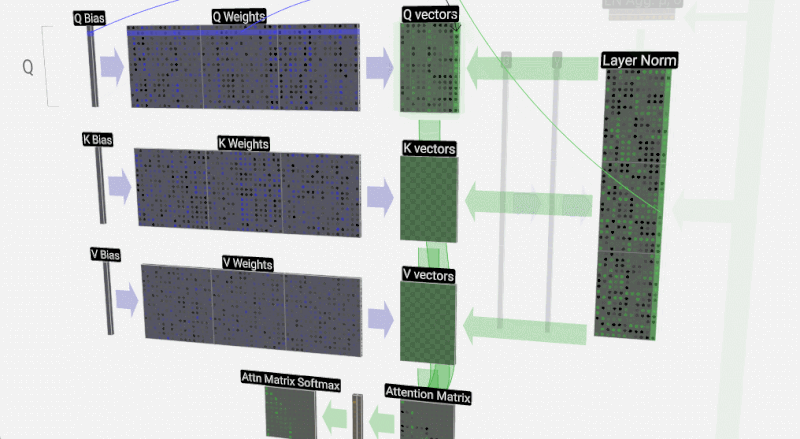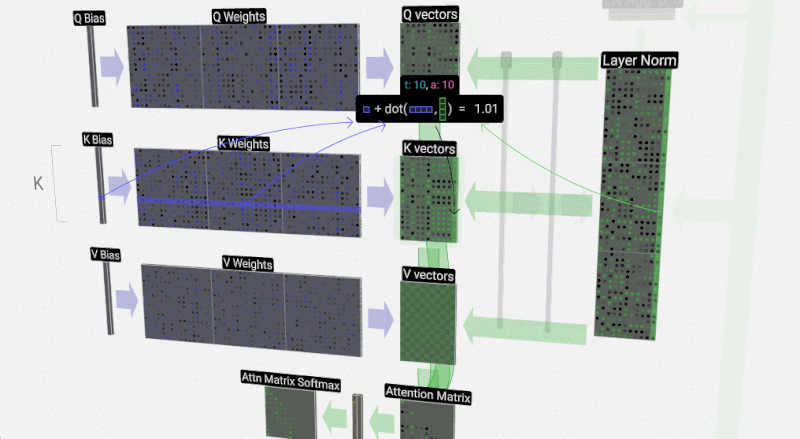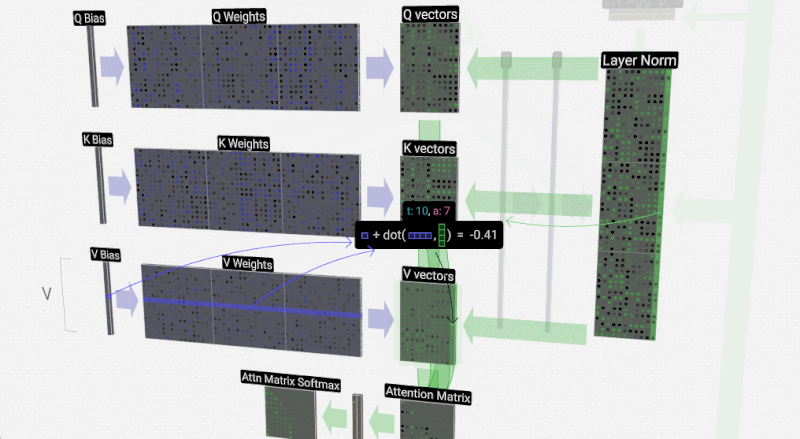
Leseprobe »Sprachmodelle Verstehen«: Womit werden Sprachmodelle trainiert?

Hinter Anwendungen künstlicher Intelligenz stecken oft Sprachmodelle. Wie diese funktionieren und welche Tücken sie mit sich bringen, erläutert Hans-Peter Stricker. Eine Rezension
Was künstliche Intelligenz mit Hilfe von Sprachmodellen leistet und wo sie dabei an Grenzen stößt, erklärt Hans-Peter Stricker. Eine Rezension (Rezension zu Sprachmodelle verstehen von Hans-Peter Stricker)#KünstlicheIntelligenz #Sprachmodell #LargeLanguageModels #KI #AI #GPT #ChatGPT #neuronal #Netze #BigData #Transformer #Prompt #Trainingsdaten #ITTech #Kultur #Mathematik #PsychologieHirnforschung
»Sprachmodelle verstehen«: Wenn aus Daten Sprache wird

Mal ein schwank aus anderen gefilden. Namentlich Telegram.
Mit ein paar bekannten dort bin ich nicht nur aktiv in einer scam aufklärungs gruppe .... sondern wie ziemlich alle anderen telegram nutzer die in verschiedenen gruppen zu finden sind, auch immer wieder selbst "opfer" von scamversuchen.
Wir haben einige kreative varianten und ideen ausprobiert, wie mensch denen am meisten auf den nerv gehen kann ggf. In schwachen momenten fragt mensch auch einfach mal nach nudes wenn eine love-scammerin sich an einen heranwerfen will..
Aber hier hat mal ein bekannter einen gänzlich anderen ansatz versucht.
Inspiriert dadurch, das neuerdings viele dieser scam-bot accounts plötzlich in der lage zu sein scheinen captchas zu lösen, was eindeutig auf den einsatz von LLM/*GPT oder sonstiger technologie schließen lässt..... Kann mensch sich das ja auch mal zu nutze machen...
Nur mal zum spass......

9 Likes
3 Comments
2 Shares
OpenAI announces GPT-4o. The "o" is for "omni". The model "can reason across audio, vision, and text in real time."
There's a series of videos showing conversation by voice, recognizing "bunny ears", two GPT-4os interacting and singing, real-time translation, lullabies and whispers, sarcasm, math problems, learning Spanish, rock paper scissors, interview prep, "Be My Eyes" accessibility, and coding assistant and desktop app.

3 Likes
2 Comments
In case you didn't realize the makers of GPT are just in it for the money,
ChatGPT maker OpenAI exploring how to 'responsibly' make AI erotica
People, even scientists, seem to think GPT and other LLMs are the shiznit. Many of my colleagues in cognitive science seem to think this and I am making myself very unpopular (probably losing colleagues) by speaking out against it.
But in case you needed any more evidence that GPT is a fundamentally commercial enterprise with no scientific merit, here you go.
GPT is business, not science, and not even real "AI". It is brute-force statistical learning whose database is practically the sum total of human knowledge.
Don't be surprised when it seems to know everything. It has been told everything.
Don't be surprised that people think it's "smart". People are fundamentally stupid.
#AI #GPT #Erotica #HumanIdiocy
https://www.npr.org/2024/05/08/1250073041/chatgpt-openai-ai-erotica-porn-nsfw

8 Likes
6 Comments
"Installation Guide for DarkGPT Project".
"DarkGPT is an artificial intelligence assistant based on GPT-4-200K designed to perform queries on leaked databases. This guide will help you set up and run the project on your local environment."
Eeep.
4 Likes
3 Comments

1 Shares
"Albania to speed up EU accession using ChatGPT".
Ok, I understood that sentence up to "using ChatGPT".
"The Albanian government will use ChatGPT to translate thousands of pages of EU legal measures and provisions into shqip (Albanian language) and then integrate them into existing legal structures, following an agreement with the CEO of the parent company, OpenAI, Mira Murati, who was born in Albania."
Oh wow, happened when Mira Murati was CEO. That was, like, a week?
So is ChatGPT the best translator for shqip because it's a smaller language? Why ChatGPT and not some other machine translation system?
"The model to be used by the Albanian government will translate into Albanian and provide a detailed overview of what and where changes need to be made to local legislation to align with EU rules. It will also provide an analysis of the impact of all measures and changes, which usually require many experts and a lot of time."
"Albanian Prime Minister Edi Rama said the move would eliminate 'an army of translators and a battalion of lawyers, costing millions of euros' and speed up the process."
So the idea is just to use ChatGPT as a translator. But is it really a good idea? Some of those "army of translators and battalion of lawyers" need to double-check all ChatGPT's work. ChatGPT is not always right.
Albania to speed up EU accession using ChatGPT - Euractiv
#solidstatelife #ai #genai #llms #gpt #mt #geopolitics #albania

2 Likes
3 Comments
ChatGPT plugins are going away. New conversations will not be allowed to use plugins on March 19, 2024. On April 9, existing conversations will not be allowed to continue.
I've been using the Wolfram|Alpha plugin. It looks like there's a "GPT" now. I'll have to try that out.
2 Likes
1 Comments
"GPTScript is a new scripting language to automate your interaction with a Large Language Model (LLM), namely OpenAI. The ultimate goal is to create a fully natural language based programming experience. The syntax of GPTScript is largely natural language, making it very easy to learn and use. Natural language prompts can be mixed with traditional scripts such as bash and python or even external HTTP service calls. With GPTScript you can do just about anything like plan a vacation, edit a file, run some SQL, or build a mongodb/flask app."
"GPTScript is composed of tools. Each tool performs a series of actions similar to a function. Tools have available to them other tools that can be invoked similar to a function call. While similar to a function, the tools are primarily implemented with a natural language prompt. The interaction of the tools is determined by the AI model, the model determines if the tool needs to be invoked and what arguments to pass. Tools are intended to be implemented with a natural language prompt but can also be implemented with a command or HTTP call."
4 Likes
Reaction video to OpenAI Sora, OpenAI's system for generating video from text.
I encountered the reaction video first, in fact I discovered Sora exists from seeing the reaction video, but see below for the official announcement from OpenAI.
It's actually kind of interesting and amusing comparing the guesses in the reaction videos about how the system works from the way it actually works. People are guessing based on their knowledge of traditional computer graphics and 3D modeling. However...
The way Sora works is quite fascinating. We don't know the knitty-gritty details but OpenAI has described the system at a high level.
Basically it combines ideas from their image generation and large language model systems.
Their image generation systems, DALL-E 2 and DALL-E 3, are diffusion models. Their large language models, GPT-2, GPT-3, GPT-4, GPT-4-Vision, etc, are transformer models. (In fact "GPT" stands for "generative pretrained transformer").
I haven't seen diffusion and transformer models combined before.
Diffusion models work by having a set of parameters in what they call "latent space" that describe the "meaning" of the image. The word "latent" is another way of saying "hidden". The "latent space" parameters are "hidden" inside the model but they are created in such a way that the images and text descriptions are correlated, which is what makes it possible to type in a text prompt and get an image out. I've elsewhere given high-level hand-wavey descriptions of how the latent space parameters are turned into images through the diffusion process, and how the text and images are correlated (a training method called CLIP), so I won't repeat that here.
Large language models, on the other hand, work by turning words and word pieces into "tokens". The "tokens" are vectors constructed in such a way that the numerical values in the vectors are related to the underlying meaning of the words.
To make a model that combines both of these ideas, they figured out a way of doing something analogous to "tokens" but for video. They call their video "tokens" "patches". So Sora works with visual "patches".
One way to think of "patches" is as video compression both spatially and temporally. Unlike a video compression algorithm such as mpeg that does this using pre-determined mathematical formulas (discrete Fourier transforms and such), in this system the "compression" process is learned and is all made of neural networks.
So with a large language model, you type in text and it outputs tokens which represent text, which are decoded to text for you. With Sora, you type in text and it outputs tokens, except here the tokens represent visual "patches", and the decoder turns the visual "patches" into pixels for you to view.
Because the "compression" works both ways, in addition to "decoding" patches to get pixels, you can also input pixels and "encode" them into patches. This enables Sora to input video and perform a wide range of video editing tasks. It can create perfectly looping video, it can animate static images (why no Mona Lisa examples, though?), it can extend videos, either forward or backward in time. Sora can gradually interpolate between two input videos, creating seamless transitions between videos with entirely different subjects and scene compositions. I found these to be the most freakishly fascinating examples on their page of sample videos.
They list the following "emerging simulation capabilities":
"3D consistency." "Sora can generate videos with dynamic camera motion. As the camera shifts and rotates, people and scene elements move consistently through three-dimensional space."
This is where they have the scene everyone is reacting to in the reaction videos, where the couple is walking down the street in Japan with the cherry blossoms.
By the way, I was wondering what kind of name is "Sora" so I looked it up on behindthename.com. It says there are two Japanese kanji characters both pronounced "sora" and both of which mean "sky".
"Long-range coherence and object permanence." "For example, our model can persist people, animals and objects even when they are occluded or leave the frame. Likewise, it can generate multiple shots of the same character in a single sample, maintaining their appearance throughout the video."
"Interacting with the world." "Sora can sometimes simulate actions that affect the state of the world in simple ways. For example, a painter can leave new strokes along a canvas that persist over time, or a man can eat a burger and leave bite marks."
"Simulating digital worlds." "Sora can simultaneously control the player in Minecraft with a basic policy while also rendering the world and its dynamics in high fidelity."
However they say, "Sora currently exhibits numerous limitations as a simulator." "For example, it does not accurately model the physics of many basic interactions, like glass shattering."
This is incredible - ThePrimeTime
#solidstatelife #ai #genai #diffusionmodels #gpt #llms #computervision #videogeneration #openai
8 Likes
6 Comments

3 Likes
1 Comments
"Comic Translate." "Many Automatic Manga Translators exist. Very few properly support comics of other kinds in other languages. This project was created to utilize the ability of GPT-4 and translate comics from all over the world. Currently, it supports translating to and from English, Korean, Japanese, French, Simplified Chinese, Traditional Chinese, Russian, German, Dutch, Spanish and Italian."
For a couple dozen languages, the best Machine Translator is not Google Translate, Papago or even DeepL, but GPT-4, and by far. This is very apparent for distant language pairs (Korean<->English, Japanese<->English etc) where other translators still often devolve into gibberish.
Works by combining neural networks for speech bubble detection, text segmentation, OCR, inpainting, translation, and text rendering. The neural networks for speech bubble detection, text segmentation, and inpainting apply to all languages, while OCR, translation, and text rendering are language-specific.
#solidstatelife #ai #computervision #mt #genai #gpt #manga #anime
3 Likes
There’s understandable excitement that Google is bringing Bard to Messages. A readymade ChatGPT-like UI for a readymade user base of hundreds of millions. “It's an AI assistant,” explains Bard’s chat when asked, “that can improve your messaging experience… from facilitating communication to enhancing creativity and providing information… it will be your personal AI assistant within your messaging app.”But Bard’s chat also acknowledges that it may ask to analyze your messages “to understand the context of your conversations, your tone, and your interests.” It may analyze the sentiment of messages, “to tailor its responses to your mood and vibe.” And it may “analyze your message history with different contacts to understand your relationship dynamics… to personalize responses based on who you're talking to.”
Is this a privacy nightmare? I don't think it will be perceived as such. Having your own AI trained on your messages and language, your personality, to help you present a better version of yourself in text or other areas will be welcomed. We love filters, make-up, editing and such things to enhance us, make us be perceived as better than what we are in the eye of other. Extending that with AI assistant help in language skills to make your writing and articulation better than you would manage on your own will be seen as valuable and a must-have.
If we create fake personas that we present and where you own persona become a hidden second-hand version, how are then we suppose get to know one another and learn to like one another for who we really are?
Anyway, as always, end-to-end encryption does not mean anything if your device is compromised, opening the door to an AI assistant on your device...you tell me how that will play out privacy-wise.
#News #AI #GPT #Chat #Message #BardAI #Privacy
Google Update Shows How Bard AI May Work With Your Messages App

Have you embraced the AI tool yet? I find myself using GPT more and more, its a great tool for questions. Actually, GPT is far superior to any web search "googling" when you just want instant answers to everything. It provide quick intro info on anything, a good base which you can use to explore or deepen your search/questioning further if needed. In contrast to web search where you have to filter lots of articles and forums to find (if ever) something useful, quite time consuming too. Its as if you have your very own Junior woodchucks guidebook in the form of GPT 😀
These are good tools: https://anonchatgpt.com/ or https://gpt4all.io/index.html
The future is exciting in the AI domain, as search engine and creativity engine they are amazing. But its also a cause for deep worry when it comes to its powers over data and possible/available offensive usage by anyone or entity. What happen when its used against you in some capacity? A tempting tool to merge all platforms and statistics on you in the blink of an eye, when algorithms decide your destiny that is a bit of a problem.
"While this first wave of AI tools is already beyond what the world could’ve imagined even just a couple of years ago, as the public adoption of AI continues we’ll only see more powerful and unique AI tools and products."
2 Likes
"Initial Prompt: You are specialized Rust engineer with tons of experience. You will tutor me on how to write great software with Rust. You will teach me all the basics to the advanced topics. You will be direct to the point and write cleaer examples for your explanations. Every code example you write will be accompanied for another example for me to complete so I can get the point."
"Let's start by you first giving me a list of topics to cover, from the very basics to the most advanced."
An experiment in learning Rust from ChatGPT instead of reading a pre-published book.

7 Likes
1 Comments
Bislang scheiterten Computer daran, komplizierte mathematische Aussagen zu beweisen. Doch nun gelang es der KI AlphaGeometry, dutzende Aufgaben der Mathematik-Olympiade zu lösen.#KI #KünstlicheIntelligenz #Mathematik-Olympiade #IMO #InternationaleMathematik-Olympiade #Geometrie #AlphaGeometry #LLM #LargeLanguageModel #GPT #Mathematik #Schule #Beweisassistent #Lean #ITTech
Eine KI könnte die Mathematik-Olympiade gewinnen

One person like that