2 Likes
1 Shares
The ZXX typeface. The site it was on, z-x-x.org, is dead. It appears cybersquatters are redirecting the domain name to some kind of browser-based spyware plugin. It now resides on GitHub and at zxx.vero.moe.
NormCap: Screen Capture Tool For Text Using OCR
https://www.linuxuprising.com/2023/05/normcap-screen-capture-tool-for-text.html
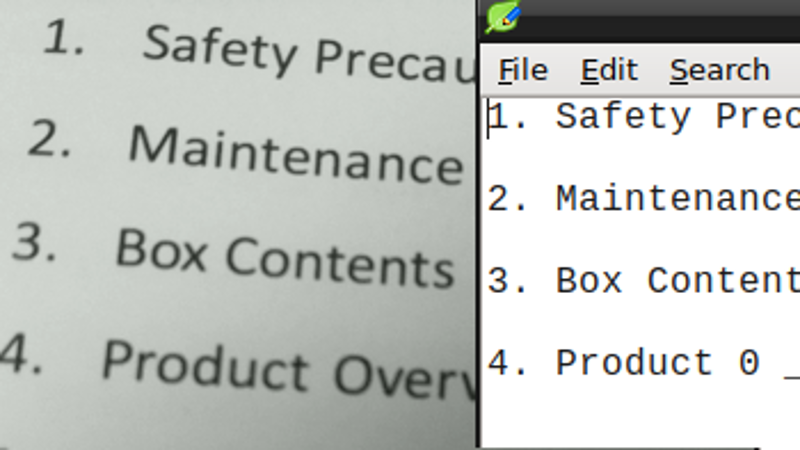
An OCR system that can convert PDFs of scientific papers dense with mathematical equations has been developed. For mathematical equations, it outputs the LaTeX format.
"Next to HTML, PDFs are the second most prominent data format on the internet, making up 2.4% of common crawl. However, the information stored in these files is very difficult to extract into any other formats. This is especially true for highly specialized documents, such as scientific research papers, where the semantic information of mathematical expressions is lost. Existing Optical Character Recognition (OCR) engines, such as Tesseract OCR, excel at detecting and classifying individual characters and words in an image, but fail to understand the relationship between them due to their line-by-line approach. This means that they treat superscripts and subscripts in the same way as the surrounding text, which is a significant drawback for mathematical expressions. In mathematical notations like fractions, exponents, and matrices, relative positions of characters are crucial. Converting academic research papers into machine-readable text also enables accessibility and searchability of science as a whole. The information of millions of academic papers can not be fully accessed because they are locked behind an unreadable format. Existing corpora, such as the S2ORC dataset, capture the text of 12M2 papers using GROBID, but are missing meaningful representations of the mathematical equations. To this end, we introduce Nougat, a transformer based model that can convert images of document pages to formatted markup text."
The researchers have released a pre-trained model capable of converting a PDF to a lightweight markup language.
"Our method is only dependent on the image of a page, allowing access to scanned papers and books."
"To the best of our knowledge there is no paired dataset of PDF pages and corresponding source code out there, so we created our own from the open access articles on arXiv. For layout diversity we also include a subset of the PubMed Central (PMC) open access non-commercial dataset. During the pretraining, a portion of the Industry Documents Library (IDL) is included."
The model they came up to do this is called Nougat, "an end-to-end trainable encoder-decoder transformer based model for converting document pages to markup." It's basically a vision transformer model.
A lot of the paper is concerted with technicalities such as splitting pages and ignoring headers and footers with page numbers and various compression and distortion artifacts, blur, and noise, that can exist in the image to be OCRed.
To measure the performance of the model, they calculated edit distance, BLEU score, METEOR score, and F1-score.
"The edit distance, or Levenshtein distance, measures the number of character manipulations (insertions, deletions, substitutions) it takes to get from one string to another. In this work we consider the normalized edit distance, where we divide by the total number of characters."
"The BLEU metric was originally introduced for measuring the quality of text that has been machinetranslated from one language to another. The metric computes a score based on the number of matching n-grams between the candidate and reference sentence.
METEOR is "another machine-translating metric with a focus on recall instead of precision."
The F1-score incorporates both precision and recall, and "We also compute the F1-score and report the precision and recall."
They compared with a previous OCR system, GROBID with LaTeX OCR. For edit distance, GROBID with LaTeX OCR got 0.727, while Nougat Small (250 million parameters) got 0.117 and Nougat Base (350 million parameters) got 0.128 on math equations. On edit distance, smaller is better. For BLUE, the numbers were 0.3 for GROBID + LaTeX OCR, 56.0 for Nougat Small and 56.9 for Nougat Base -- larger is better. On METEOR, the numbers were 5.0 for GROBID + LaTeX OCR, 74.7 for Nougat Small and 75.4 for Nougat Base -- larger is better. For F1, the numbers were 9.7 for GROBID + LaTeX OCR, 76.9 for Nougat Small, and 76.5 for Nougat Base -- larger is better.
This sounds like something that could be incredibly useful.
Machmal wäre ja eine gute #Formelsammlung für #Elektrotechnik echt hilfreich, sowas was früher allgemein #Tabellenbuch genannt wurde und in der #Berufsschule oder anfangs im #Studium verwendet wurde. Aber nen Buch mit rumschleppen ist eher nicht schön. Gibt es da was gutes als PDF, sonst kaufe ich mir ein Buch und scanne das ein, wenn man den Rücken abschneidet geht das ja recht gut. #OCR ist nicht perfekt, aber funktioniert mittlerweile auch ganz OK.
I wonder if someone could setup an #OCR #bot on a #Friendica server, after all it got the #Mastodon API for apps, so it should be possible.
Anyone here to volunteer and setup an ocr bot to transcribe text in pictures? Would be great to be triggered by hash tag or mention.
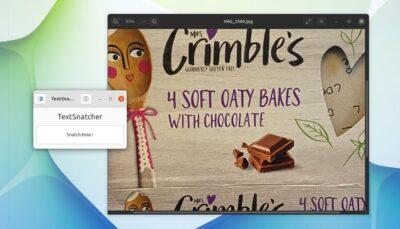
Being able to extract text from photos, PDFs and the like isn’t something new. Indeed, many ace tools exist for the job, including several well-regarded command line ones available on Linux. But being able to do it very easily? That is new.
With modern operating systems like macOS and Android making image OCR an integrated feature of their native image viewer tools or photo managers, it’s understandable that some folks new to Ubuntu, Linux Mint, and other distros expect similar functionality.
And with TextSnatcher, they do. The tool performs optical character recognition (OCR) in seconds, allowing you to quickly copy text from anything visible on your screen to your system clipboard, ready to paste elsewhere.
This application’s interface couldn’t be easier to use: you open it, click the “snatch” button, then use your DEs default screenshot tool to take a full screenshot or partial screenshot (recommended) focusing on just the text you want to copy.
See https://www.omgubuntu.co.uk/2022/02/textsnatcher-copy-text-from-images-linux
#technology #opensource #ocr #linux
#Blog, ##linux, ##ocr, ##opensource, ##technology
12 Best #FreeSW #OCR Tools • Tux Machines ⇨ http://www.tuxmachines.org/node/158441 #GNU #Linux #TuxMachines
#Tesseract 5.0 #OCR Engine Bringing Faster Performance With "Fast Floats" • 𝗧𝘂𝘅 𝗠𝗮𝗰𝗵𝗶𝗻𝗲𝘀 ⇨ http://www.tuxmachines.org/node/154573 #deletegithub #microsoft http://techrights.org/wiki/index.php/Delete_Github