Internet Archive's Wayback Machine APIs
Say, for the sake of argument, that you've^†^ spent a few weeks trying to ensure that a set of URLs were archived at the Internet Archive's Wayback Machine, and you're aware that not all of those URLs were in fact archived, but you^†^ aren't sure just which ones were or were not.
The question might occur to you^†^, "Is there some way of testing whether or not a particular URL has or has not been successfully archived? Preferably in an automated manner?"
And the answer to that question would be YES!!! Yes there is!!!
What you^†^ are looking for are the Internet Archive Wayback Machine APIs, and specifically:
Wayback Availability JSON API
This simple API for Wayback is a test to see if a given url is archived and currenlty accessible in the Wayback Machine. This API is useful for providing a 404 or other error handler which checks Wayback to see if it has an archived copy ready to display.
Quoting from the Archive:
The API can be used as follows:
http://archive.org/wayback/available?url=example.com
which might return:
{
"archived_snapshots": {
"closest": {
"available": true,
"url": "http://web.archive.org/web/20130919044612/http://example.com/",
"timestamp": "20130919044612",
"status": "200"
}
}
}
if the url is available. When available, the url is the link to the archived snapshot in the Wayback Machine At this time, archived_snapshots just returns a single closest snapshot, but additional snapshots may be added in the future.
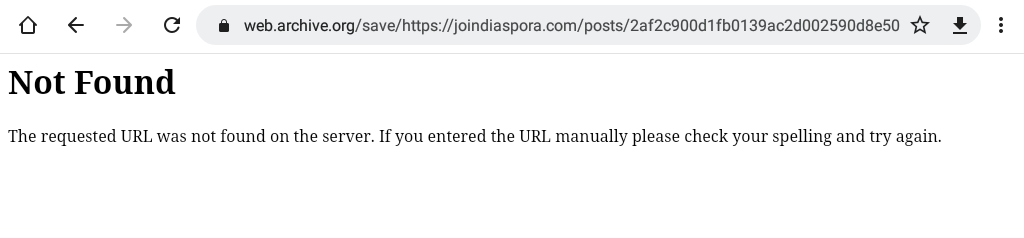
If the url is not available (not archived or currently not accessible), the response will be:
{"archived_snapshots":{}}
https://archive.org/help/wayback_api.php
It's also possible to query for a specific timestamp, though not AFAICT for saves within a date range.
You^†^ are now running that check on a set of 1300 or so URLs you'd^†^ hoped to have saved in the past two months or so.
See Also: Data Migration Tips and Questions.
Notes:
†: And my "you" I of course me "me".
#DataMigration #InternetArchive #APIs #Joindiaspora #JoindiasporaCom #Pluspora #Archival